
6.3: 操作条件调节
- Page ID
- 203780

| 经典调理 | 操作员调节 | |
|---|---|---|
| 调理方法 | 无条件刺激(例如食物)与中性刺激(例如铃铛)配对。 中性刺激最终变成了条件刺激,它带来了条件性反应(流涎)。 | 目标行为之后是强化或惩罚,以强化或削弱它,这样学习者将来更有可能表现出想要的行为。 |
| 刺激时机 | 刺激发生在反应之前。 | 刺激(强化或惩罚)发生在反应后不久。 |
心理学家 B. F. Skinner 认为,传统条件仅限于反身引发的现有行为,它不包括骑自行车等新行为。 他提出了一个关于这种行为是如何产生的理论。 斯金纳认为,行为的动机是我们因行为而受到的后果:增援和惩罚。 他认为学习是后果的结果的观点是基于心理学家爱德华·桑代克最初提出的效果定律。 根据效果定律,随之而来的是令生物体满意的后果的行为更有可能重演,而随后出现不愉快后果的行为则不太可能重演(Thorndike,1911)。 从本质上讲,如果一个生物体做了能带来预期结果的事情,那么该生物体更有可能再次这样做。 如果一个生物体做了不能带来预期结果的事情,那么该生物体就不太可能再做一次。 效应法则的一个例子是就业。 我们上班的原因之一(通常也是主要原因)是因为我们因此获得报酬。 如果我们停止获得报酬,即使我们热爱我们的工作,我们也可能会停止露面。
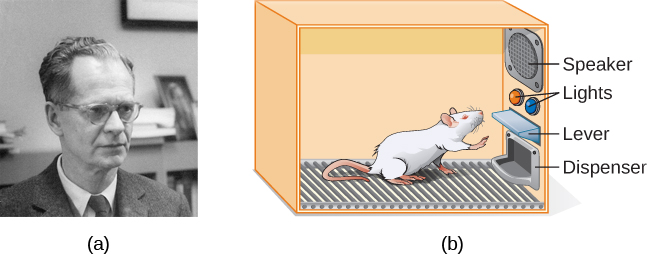
斯金纳以桑代克的效应定律为基础,开始对动物(主要是老鼠和鸽子)进行科学实验,以确定生物如何通过操作条件学习(Skinner,1938 年)。 他将这些动物放在操作员调理室内,该室后来被称为 “Skinner box”(图 6.10)。 Skinner 盒子里有一个杠杆(用于老鼠)或圆盘(用于鸽子),动物可以通过分配器按下或啄食以获得食物奖励。 扬声器和灯光可能与某些行为相关联。 记录器计算动物的反应次数。
| 正面和负面的强化与惩罚 | ||
|---|---|---|
| 加固 | 惩罚 | |
| 阳性 | 添加了一些东西来增加行为发生的可能性。 | 添加了一些东西来降低行为发生的可能性。 |
| 负面的 | 移除某些东西以增加发生行为的可能性。 | 移除某些内容以降低行为发生的可能性。 |
加固
教导人或动物新行为的最有效方法是积极强化。 在正向强化中,添加了理想的刺激来增加行为。
例如,你告诉你五岁的儿子杰罗姆,如果他打扫房间,他会得到一个玩具。 杰罗姆很快就打扫了房间,因为他想要一套新的艺术套装。 让我们暂停片刻。 有些人可能会说:“我为什么要奖励我的孩子做了预期的事情?” 但实际上,我们在生活中不断获得回报。 我们的薪水是奖励,高分和被我们首选学校录取也是如此。 因表现出色和通过驾驶员考试而受到称赞也是一种奖励。 积极强化作为一种学习工具非常有效。 研究发现,在阅读分数低于平均水平的学区提高成绩的最有效方法之一是付钱给孩子读书。 具体而言,达拉斯的二年级学生每次读一本书并通过关于这本书的简短测验可获得2美元的报酬。 结果是阅读理解能力显著提高(Fryer,2010)。 你觉得这个程序怎么样? 如果斯金纳今天还活着,他可能会认为这是个好主意。 他坚决支持使用操作条件原则来影响学生在学校的行为。 事实上,除了 Skinner Box 之外,他还发明了他所谓的教学机器,旨在奖励学习中的小步骤(Skinner,1961 年),这是计算机辅助学习的早期先驱。 他的教学机器测试了学生在学习各种学校科目时的知识。 如果学生正确回答问题,他们会立即得到积极的强化并可以继续;如果他们回答不正确,他们就不会得到任何强化。 当时的想法是让学生花更多时间学习材料,以增加他们下次获得强化的机会(Skinner,1961 年)。
在负强化中,消除不良刺激以增加行为。 例如,汽车制造商在其安全带系统中使用负加固原理,在你系好安全带之前,安全带会发出 “哔声、哔哔声、哔声”。 当你表现出想要的行为时,烦人的声音就会停止,这增加了你将来屈服的可能性。 负强化也经常用于骑马训练。 骑手施加压力(通过拉动缰绳或挤压双腿),然后在马匹表现出所需的行为(例如转弯或加速)时移除压力。 压力是马匹想要消除的负面刺激。
惩罚
许多人将负面强化与手术条件中的惩罚混为一谈,但它们是两种截然不同的机制。 请记住,强化,即使是负面的,也总是会增加行为。 相比之下,惩罚总是会减少行为。 在正面惩罚中,你添加了不良刺激来减少行为。 正面惩罚的一个例子是责骂学生让学生停止在课堂上发短信。 在这种情况下,添加了刺激(谴责)以减少行为(课堂上发短信)。 在负面惩罚中,你可以消除愉快的刺激以减少行为。 例如,当孩子行为不端时,父母可以带走最喜欢的玩具。 在这种情况下,刺激(玩具)被移除以减少行为。
惩罚,尤其是立即惩罚时,是减少不良行为的一种方法。 例如,假设你四岁的儿子布兰登打了他的弟弟。 你让布兰登写了 100 次 “我不会打我的兄弟”(正面惩罚)。 他很可能不会重复这种行为。 尽管这种策略在当今很普遍,但过去儿童经常受到体罚,例如打屁股。 重要的是要意识到对儿童使用体罚的一些弊端。 首先,惩罚可能会教会恐惧。 布兰登可能会害怕街头,但他也可能会害怕施加惩罚的人 —— 你的父母。 同样,受到教师惩罚的孩子可能会害怕老师,试图逃学(Gershoff 等人,2010 年)。 因此,美国的大多数学校都禁止体罚。 其次,惩罚可能使儿童变得更具攻击性,更容易出现反社会行为和违法行为(Gershoff,2002)。 他们看到父母在生气和沮丧时会打屁股,因此,反过来,当他们生气和沮丧时,他们可能会表现出同样的行为。 例如,当你因为布伦达的不当行为而生她的气时,你就打她一巴掌,所以当朋友不愿分享玩具时,她可能会开始打她的朋友。
尽管在某些情况下,积极惩罚可能有效,但斯金纳建议,应权衡惩罚的使用和可能的负面影响。 今天的心理学家和育儿专家更倾向于强化而不是惩罚——他们建议你抓住孩子做一些好事,并为此奖励她。
塑形
在他的操作条件实验中,斯金纳经常使用一种叫做成形的方法。 在塑造中,我们不是只奖励目标行为,而是奖励连续近似的目标行为。 为什么需要塑形? 请记住,为了使强化发挥作用,生物体必须首先表现出行为。 之所以需要塑造,是因为除了最简单的行为之外,生物体极不可能自发地表现出任何东西。 在塑造过程中,行为被分解为许多小的、可实现的步骤。 该过程中使用的具体步骤如下:
塑形通常用于教导复杂的行为或一系列行为。 斯金纳使用塑形不仅教鸽子在斯金纳盒子里啄圆盘等相对简单的行为,还教了许多不寻常且有趣的行为,例如转圈、用八位数行走,甚至打乒乓球;这种技巧现在被动物训练师普遍使用。 塑造的一个重要部分是刺激歧视。 回想一下巴甫洛夫的狗——他训练它们对铃声做出反应,而不是对相似的音调或声音做出反应。 这种歧视在操作条件和行为塑造方面也很重要。
不难看出塑形在向动物传授行为方面有多有效,但是塑造对人类有何作用? 让我们以父母为例,他们的目标是让孩子学会打扫房间。 他们使用塑形来帮助他掌握实现目标的步骤。 他们没有执行整个任务,而是设置了这些步骤并强化了每个步骤。 首先,他要清理一个玩具。 其次,他清理了五个玩具。 第三,他选择是拿起十个玩具还是把书和衣服收起来。 第四,他清理了除两个玩具之外的所有东西。 最后,他打扫了整个房间。
初级和次要强化部队
贴纸、赞美、金钱、玩具等奖励可用于强化学习。 让我们再回到斯金纳的老鼠身边。 老鼠是怎么学会按下 Skinner 箱子里的杠杆的? 每当他们按下杠杆时,他们都会获得食物奖励。 对于动物来说,食物显然是一种强化剂。
对人类来说,什么才是好的强化剂? 对你的孩子 Chris 来说,这是他们打扫房间时会有玩具的承诺。 足球运动员悉尼怎么样? 如果你每次悉尼进球时都给悉尼一块糖果,那么你就是在使用初级强化器。 初级强化剂是具有与生俱来的强化品质的强化剂。 这类强化器是没学过的。 水、食物、睡眠、避难所、性和触摸等是主要的强化因素。 快乐也是主要的强化手段。 生物不会因为这些东西而失去动力。 对于大多数人来说,在非常炎热的天气里跳入凉爽的湖泊会得到加强,而凉爽的湖泊天生就会增强 —— 水会使人降温(一种身体需求),同时提供快乐。
次要强化器没有固有价值,只有在与初级强化器连接时才具有强化品质。 赞美与情感相关,是次要强化剂的一个例子,就像你喊出 “好镜头!” 时一样 每次悉尼进球时。 另一个例子,金钱,只有当你能用它来购买其他东西时才有价值,要么是满足基本需求的东西(食物、水、避难所——都是主要的强化物),要么是其他次要强化物。 如果你在太平洋中部的偏远岛屿上,你有成堆的钱,那么如果你不花钱,这笔钱就没用了。 行为图表上的贴纸呢? 它们也是次要的强化剂。
有时,不是在贴纸图表上贴纸,而是使用代币。 代币也是次要强化剂,然后可以用来换取奖励和奖品。 整个行为管理系统,即代币经济,是围绕使用此类代币增强剂而建立的。 人们发现,代币经济在改变学校、监狱和精神病院等各种环境中的行为方面非常有效。 例如,Cangi和Daly(2013)的一项研究发现,使用代币经济可以增加一组自闭症学童的适当社交行为并减少不当行为。 自闭症儿童往往表现出破坏性行为,例如捏和殴打。 当研究中的孩子表现出适当的行为(不是打或捏)时,他们会收到一个 “安静的双手” 代币。 当他们击中或捏住时,他们丢失了一个代币。 然后,孩子们可以用指定数量的代币兑换几分钟的游戏时间。

超时是另一种常用的技巧,用于改变孩子的行为。 它以负面惩罚的原则运作。 当孩子表现出不良行为时,她将脱离手头的理想活动(图6.12)。 例如,假设索菲亚和她的兄弟马里奥在玩积木。 索菲亚向她哥哥扔了一些方块,所以你警告她如果再这样做她就会超时。 几分钟后,她向马里奥投掷了更多方块。 你把索菲亚从房间里移走几分钟。 当她回来时,她不会扔方块。
如果你打算将超时作为一种行为修改技术来实现,你应该知道几个重要点。 首先,确保将孩子从理想的活动中带走,并将其安置在不太理想的位置。 如果这种活动对孩子来说是不可取的,那么这种技巧将适得其反,因为让孩子退出活动会更愉快。 其次,超时时间很重要。 一般的经验法则是孩子的年龄每年一分钟。 索菲亚已经五岁了;因此,她暂停了五分钟。 设置计时器可以帮助孩子知道他们需要坐多长时间才能超时。 最后,作为看护者,在超时期间要记住几个指导方针:引导孩子超时时保持冷静;在超时期间忽略孩子(因为看护者的注意力可能会加剧不当行为);在超时结束时给孩子一个拥抱或说一句客气话。

加固时间表
请记住,教人或动物行为的最好方法是使用积极的强化。 例如,斯金纳使用正向强化来教老鼠按下 Skinner 盒子里的杠杆。 起初,老鼠在探索盒子时可能会随机击中杠杆,然后会出现一团食物。 吃了颗粒后,你认为那只饥饿的老鼠接下来做了什么? 它又撞到了杠杆,又收到了一粒食物。 每当老鼠碰到杠杆时,都会流出一粒食物。 当生物体每次表现出某种行为时都获得强化剂时,它被称为持续强化。 这种强化计划是教别人行为的最快方法,在训练新行为方面特别有效。 让我们回顾一下本章前面那只正在学习坐着的狗。 现在,他每次坐下,你都要给他一种享受。 在这里,时机很重要:如果你在他坐下后立即出示强化器,这样他就可以将目标行为(坐着)和后果(得到治疗)联系起来,你将取得最大的成功。
| 加固时间表 | |||
|---|---|---|---|
| 增援时间表 | 描述 | 结果 | 示例 |
| 固定间隔 | 增援以可预测的时间间隔(例如,在 5、10、15 和 20 分钟后)交付。 | 反应速度适中,强化后会有明显的停顿 | 住院患者使用患者控制、医生定时缓解疼痛 |
| 可变间隔 | 增援以不可预测的时间间隔(例如,在 5、7、10 和 20 分钟后)交付。 | 中等但稳定的回应率 | 查看 Facebook |
| 固定比率 | 强化是在可预测的响应数量之后进行的(例如,在 2、4、6 和 8 次响应之后)。 | 响应速度快,加固后会暂停 | 计件工作——工厂工人每生产 x 件物品就能获得报酬 |
| 可变比率 | 强化是在不可预测的响应次数之后进行的(例如,在 1、4、5 和 9 次响应之后)。 | 高而稳定的响应率 | 赌博 |
现在让我们把这四个术语结合起来。 固定间隔强化时间表是指在设定的时间后行为获得奖励。 例如,六月在医院接受了大手术。 在康复期间,她预计会感到疼痛,需要处方药来缓解疼痛。 June 使用患者控制的止痛药进行静脉滴注。 她的医生设定了限量:每小时一剂。 当疼痛变得困难时,June 按下按钮,她会接受一定剂量的药物。 由于奖励(缓解疼痛)仅在固定的间隔内发生,因此在没有奖励的情况下展示这种行为是没有意义的。
在可变间隔强化计划下,人或动物根据不同的时间获得增援,这是不可预测的。 假设曼努埃尔是一家快餐店的经理。 每隔一段时间,质量控制部门就会有人来到曼努埃尔的餐厅。 如果餐厅很干净而且服务很快,那么轮班的每个人都将获得20美元的奖金。 曼努埃尔不知道质量控制人员何时出现,因此他总是努力保持餐厅的清洁,并确保员工提供及时而有礼貌的服务。 他在提供及时服务和保持餐厅清洁方面的工作效率保持稳定,因为他希望员工获得奖金。
在固定比率的强化计划下,在行为获得奖励之前,必须进行一定数量的回应。 卡拉在一家眼镜店卖眼镜,每卖一副眼镜她都会赚取佣金。 她总是尝试向人们出售更多的眼镜,包括处方太阳镜或备用太阳镜,这样她就可以增加佣金。 她不在乎这个人是否真的需要处方太阳镜,卡拉只想要她的奖金。 卡拉销售的商品的质量无关紧要,因为她的佣金不是基于质量的;它仅基于售出的双数量。 这种性能质量的区别可以帮助确定哪种加固方法最适合特定情况。 固定比率更适合优化产出数量,而固定间隔(奖励不是基于数量)可以提高产出质量。
在可变比率的强化计划中,获得奖励所需的回应数量各不相同。 这是最强大的部分强化计划。 可变比率强化计划的一个例子是赌博。 想象一下,莎拉(通常是个聪明、节俭的女人)第一次访问拉斯维加斯。 她不是赌徒,但出于好奇,她在老虎机上投入了四分之一,然后又投入了另一个。 什么都没发生。 两个季度后,她的好奇心逐渐消失,她马上就要辞职了。 但是随后,机器亮了,钟声响了,莎拉又回来了 50 个季度。 更像这样! 莎拉带着新的利息回到了插入季度,几分钟后,她已经用尽了所有收益,漏洞里有10美元。 现在可能是戒烟的明智时机。 但是,她一直在向老虎机投入资金,因为她不知道下一次增援何时到来。 她一直认为,在下个季度她可以赢取50美元、100美元甚至更多。 由于大多数赌博类型的强化时间表都有可变比率时间表,因此人们一直在努力,希望下次他们能大获全胜。 这是赌博如此容易上瘾、如此难以灭绝的原因之一。
在操作条件下,强化行为的消失发生在加固停止后的某个时候,这种情况发生的速度取决于加固时间表。 如上所述,在可变比率时间表中,消失点来得非常缓慢。 但是在其他增援计划中,灭绝可能很快就会到来。 例如,如果 June 在医生批准的规定时间之前按下止痛药的按钮,则不会服用任何药物。 她按固定的间隔增援计划(每小时给药),因此当增援没有在预期的时间到来时,灭绝很快就会发生。 在加固计划中,可变比率是生产力最高的,最能抵抗消光的。 固定间隔是生产力最低且最容易熄灭的(图 6.13)。
斯金纳(1953)表示:“如果赌博机构无法说服顾客在没有回报的情况下交钱,则可以通过按可变比率计划退还顾客的部分资金来达到同样的效果”(第397页)。
斯金纳以赌博为例,说明可变比率强化计划的力量,即使在长时间没有任何强化的情况下也能保持行为。 事实上,斯金纳对自己对赌博成瘾的了解非常有信心,以至于他甚至声称自己可以把鸽子变成病态的赌徒(《斯金纳的乌托邦》,1971 年)。 的确,可变比率的时间表可以使行为保持相当持久——试想一下,如果父母对这种行为屈服一次,孩子发脾气的频率是多少。 偶尔的奖励使得停止这种行为几乎是不可能的。
最近对老鼠的研究未能支持斯金纳的观点,即仅按可变比率时间表进行训练就会导致病态赌博(Laskowski等人,2019年)。 但是,其他研究表明,赌博对大脑的作用似乎与大多数成瘾药物相同,因此大脑化学和强化时间表的某种组合可能会导致问题赌博(图 6.14)。 具体而言,现代研究表明,赌博与激活使用神经递质(大脑化学物质)多巴胺的大脑奖励中心之间存在联系(Murch & Clark,2016)。 有趣的是,赌徒甚至不必赢就能体验大脑中多巴胺的 “冲动”。 事实证明,“差点失误”,或者差点赢但实际上没有获胜,也会增加腹侧纹状体和其他使用多巴胺的大脑奖励中心的活动(Chase & Clark,2010)。 这些大脑效应与可卡因和海洛因等成瘾药物产生的效应几乎相同(Murch & Clark,2016年)。 根据显示这些相似之处的神经科学证据,DSM-5 现在将赌博视为成瘾,而早期版本的 DSM 将赌博归类为冲动控制障碍。
除多巴胺外,赌博似乎还涉及其他神经递质,包括去甲肾上腺素和血清素(Potenza,2013)。 当一个人感到压力、觉醒或刺激时,就会分泌去甲肾上腺素。 可能是病态赌徒利用赌博来增加这种神经递质的水平。 血清素的缺乏也可能导致强迫行为,包括赌博成瘾(Potenza,2013)。
可能是病态赌徒的大脑与其他人的大脑不同,也许这种差异可能以某种方式导致了他们的赌博成瘾,正如这些研究似乎表明的那样。 但是,很难确定原因,因为不可能进行真正的实验(试图将随机分配的参与者变成问题赌徒是不道德的)。 因此,可能是因果关系实际上朝着相反的方向移动——也许赌博行为以某种方式改变了某些赌徒大脑中的神经递质水平。 一些被忽视的因素或混淆变量也可能在赌博成瘾和大脑化学差异中起了作用。
认知与潜在学习
像沃森和斯金纳这样的严格的行为主义者只专注于研究行为而不是认知(例如思想和期望)。 事实上,斯金纳是一个非常坚定的信徒,认知他的想法被认为是激进的行为主义并不重要。 斯金纳认为心灵是一个 “黑匣子” —— 这是完全不可知的东西 —— 因此,这是不值得研究的东西。 但是,另一位行为学家爱德华·托尔曼却有不同的看法。 托尔曼对老鼠的实验表明,即使生物没有立即得到强化,它们也可以学习(Tolman & Honzik,1930 年;Tolman、Ritchie 和 Kalish,1946 年)。 这一发现与当时流行的观念相矛盾,即必须立即进行强化才能进行学习,因此暗示了学习的认知方面。
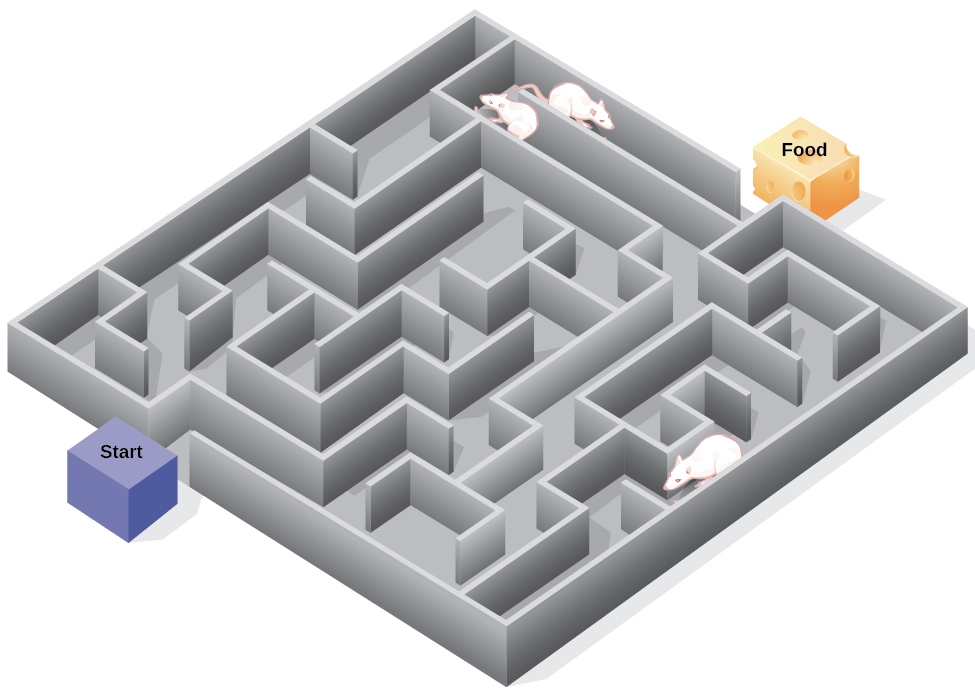
在实验中,托尔曼将饥饿的老鼠放入迷宫中,找到穿越迷宫的出路没有任何奖励。 他还研究了一个比较小组,该小组在迷宫尽头获得了食物奖励。 当未强化的大鼠探索迷宫时,他们绘制了一张认知地图:迷宫布局的心理画面(图 6.15)。 在没有强化的情况下在迷宫中进行 10 次训练后,食物被放入迷宫尽头的目标箱中。 老鼠一意识到食物,它们就能迅速找到穿越迷宫的出路,就像对照组一样快,后者一直获得食物奖励。 这就是所谓的潜在学习:学习发生了,但在有理由证明之前无法在行为中观察到。
你有没有在建筑物里迷路而找不到回来的路? 虽然这可能令人沮丧,但你并不孤单。 我们都曾在博物馆、医院或大学图书馆等地方迷路了。 每当我们去一个新的地方时,我们都会绘制出该位置的心理表现或认知地图,就像托尔曼的老鼠们绘制了迷宫的认知地图一样。 但是,有些建筑物之所以令人困惑,是因为它们包括许多看起来相似或视线较短的区域。 因此,通常很难预测拐角处会发生什么,也很难决定是向左还是向右转才能离开建筑物。 心理学家劳拉·卡尔森(Laura Carlson)(2010)认为,我们在认知地图中的位置会影响我们在环境中导航的成功。 她建议,在进入建筑物时注意特定特征,例如墙上的照片、喷泉、雕像或自动扶梯,可以为我们的认知地图添加信息,这些信息可以在以后用来帮助我们找到离开建筑物的出路。