
2.8: Hatua za Kuenea kwa Data
- Page ID
- 181072

Tabia muhimu ya seti yoyote ya data ni tofauti katika data. Katika seti fulani za data, maadili ya data yanajilimbikizia karibu na maana; katika seti nyingine za data, maadili ya data yanaenea zaidi kutoka kwa maana. Kipimo cha kawaida cha tofauti, au kuenea, ni kupotoka kwa kawaida. Kupotoka kwa kiwango ni namba inayopima jinsi maadili ya data yanatoka kwa maana yao.
Mkengeuko wa kawaida
- hutoa kipimo namba ya jumla ya kiasi cha tofauti katika kuweka data, na
- inaweza kutumika kuamua kama thamani fulani ya data iko karibu au mbali na maana.
Mkengeuko wa kawaida hutoa kipimo cha tofauti ya jumla katika kuweka data
Kupotoka kwa kawaida daima ni chanya au sifuri. Kupotoka kwa kawaida ni ndogo wakati data zote zimejilimbikizia karibu na maana, kuonyesha tofauti kidogo au kuenea. Kupotoka kwa kiwango ni kubwa wakati maadili ya data yanaenea zaidi kutoka kwa maana, kuonyesha tofauti zaidi.
Tuseme kwamba sisi ni kusoma kiasi cha wateja wakati kusubiri katika mstari katika Checkout katika maduka makubwa A na maduka makubwa B. wastani wa kusubiri wakati katika maduka makubwa yote ni dakika tano. Katika maduka makubwa A, kupotoka kwa kawaida kwa muda wa kusubiri ni dakika mbili; katika maduka makubwa B kupotoka kwa muda wa kusubiri ni dakika nne.
Kwa sababu maduka makubwa B ina juu ya kiwango kupotoka, tunajua kwamba kuna tofauti zaidi katika nyakati kusubiri katika maduka makubwa B. Kwa ujumla, kusubiri mara katika maduka makubwa B ni zaidi kuenea nje kutoka wastani; kusubiri mara katika maduka makubwa A ni zaidi kujilimbikizia karibu wastani.
Kupotoka kwa kawaida kunaweza kutumika kuamua kama thamani ya data iko karibu au mbali na maana.
Tuseme kwamba Rosa na Binh wote duka katika maduka makubwa A. Rosa anasubiri kwenye counter ya checkout kwa dakika saba na Binh anasubiri dakika moja. Katika maduka makubwa A, muda wa kusubiri wastani ni dakika tano na kupotoka kwa kawaida ni dakika mbili. Kupotoka kwa kawaida kunaweza kutumika kuamua kama thamani ya data iko karibu au mbali na maana.
Rosa anasubiri kwa dakika saba:
- Saba ni dakika mbili zaidi ya wastani wa tano; dakika mbili ni sawa na kupotoka kwa kiwango kimoja.
- Muda wa kusubiri wa Rosa wa dakika saba ni dakika mbili zaidi kuliko wastani wa dakika tano.
- Muda wa kusubiri wa Rosa wa dakika saba ni kupotoka kwa kiwango kimoja juu ya wastani wa dakika tano.
Binh anasubiri dakika moja.
- Moja ni dakika nne chini ya wastani wa tano; dakika nne ni sawa na upungufu wa kiwango mbili.
- Muda wa kusubiri wa Binh wa dakika moja ni dakika nne chini ya wastani wa dakika tano.
- Wakati wa kusubiri wa Binh wa dakika moja ni upungufu wa kiwango cha chini chini ya wastani wa dakika tano.
- Thamani ya data ambayo ni upungufu wa kiwango mbili kutoka kwa wastani ni kwenye mpaka wa mpaka kwa nini wanatakwimu wengi watafikiria kuwa mbali na wastani. Kuzingatia data kuwa mbali na maana ikiwa ni zaidi ya mbili kupotoka kiwango mbali ni zaidi ya takriban “utawala wa kidole” kuliko utawala rigid. Kwa ujumla, sura ya usambazaji wa data huathiri kiasi gani cha data kilicho mbali zaidi kuliko vikwazo viwili vya kawaida. (Utajifunza zaidi kuhusu hili katika sura za baadaye.)
Nambari ya nambari inaweza kukusaidia kuelewa kupotoka kwa kiwango. Kama tungekuwa na kuweka tano na saba kwenye mstari namba, saba ni haki ya tano. Tunasema, basi, kwamba saba ni moja ya kiwango kupotoka na haki ya tano kwa sababu\(5 + (1)(2) = 7\).
Ikiwa moja pia ilikuwa sehemu ya kuweka data, basi moja ni upungufu wa kiwango mbili upande wa kushoto wa tano kwa sababu\(5 + (-2)(2) = 1\).

- Kwa ujumla, thamani = maana + (#ofSTDEV) (kupotoka kwa kiwango)
- ambapo #ofSTDEVs = idadi ya upungufu wa kawaida
- #ofSTDEV haina haja ya kuwa integer
- Moja ni mbili kupotoka kiwango chini ya maana ya tano kwa sababu:\(1 = 5 + (-2)(2)\).
Thamani ya equation = maana + (#ofSTDEVs) (kupotoka kwa kawaida) inaweza kuelezwa kwa sampuli na kwa idadi ya watu.
- sampuli:\[x = \bar{x} + \text{(#ofSTDEV)(s)}\]
- Idadi ya watu:\[x = \mu + \text{(#ofSTDEV)(s)}\]
kesi ya chini barua s inawakilisha sampuli kiwango kupotoka na barua Kigiriki\(\sigma\) (sigma, kesi ya chini) inawakilisha idadi ya watu kiwango kupotoka.
Ishara\(\bar{x}\) ni sampuli maana na ishara ya Kigiriki\(\mu\) ni maana ya idadi ya watu.
Kuhesabu kupotoka kwa kiwango
Ikiwa\(x\) ni namba, basi tofauti "\(x\)— maana” inaitwa kupotoka kwake. Katika kuweka data, kuna vikwazo vingi kama kuna vitu katika kuweka data. Ukosefu hutumiwa kuhesabu kupotoka kwa kawaida. Kama idadi ni mali ya idadi ya watu, katika alama kupotoka ni\(x - \mu\). Kwa data sampuli, katika alama kupotoka ni\(x - \bar{x}\).
Utaratibu wa kuhesabu kupotoka kwa kiwango unategemea kama namba ni idadi nzima au ni data kutoka kwa sampuli. Mahesabu ni sawa, lakini si sawa. Kwa hiyo ishara inayotumiwa kuwakilisha kupotoka kwa kiwango inategemea iwapo imehesabiwa kutoka kwa idadi ya watu au sampuli. kesi ya chini barua s inawakilisha sampuli kiwango kupotoka na barua Kigiriki\(\sigma\) (sigma, kesi ya chini) inawakilisha idadi ya watu kiwango kupotoka. Ikiwa sampuli ina sifa sawa na idadi ya watu, basi s lazima iwe makadirio mazuri ya\(\sigma\).
Ili kuhesabu kupotoka kwa kawaida, tunahitaji kuhesabu ugomvi kwanza. Tofauti ni wastani wa mraba wa upungufu (\(x - \bar{x}\)maadili ya sampuli, au\(x - \mu\) maadili kwa idadi ya watu). ishara\(\sigma^{2}\) inawakilisha ugomvi idadi ya watu; idadi ya watu kiwango kupotoka\(\sigma\) ni mizizi mraba ya ugomvi idadi ya watu. ishara\(s^{2}\) inawakilisha sampuli ugomvi; sampuli kiwango kupotoka s ni mizizi mraba ya sampuli ugomvi. Unaweza kufikiria kupotoka kwa kawaida kama wastani maalum wa upungufu.
Ikiwa namba zinatokana na sensa ya idadi ya watu wote na sio sampuli, tunapohesabu wastani wa upungufu wa mraba ili kupata ugomvi, tunagawanya na\(N\), idadi ya vitu katika idadi ya watu. Kama data ni kutoka sampuli badala ya idadi ya watu, wakati sisi mahesabu ya wastani wa kupotoka squared, sisi kugawanya na n — 1, moja chini ya idadi ya vitu katika sampuli.
Fomu za Kupotoka kwa kiwango cha Mfano
\[s = \sqrt{\dfrac{\sum(x-\bar{x})^{2}}{n-1}} \label{eq1}\]
au
\[s = \sqrt{\dfrac{\sum f (x-\bar{x})^{2}}{n-1}} \label{eq2}\]
Kwa kupotoka kwa kiwango cha sampuli, denominator ni\(n - 1\), yaani ukubwa wa sampuli MINUS 1.
Fomu za Kupotoka kwa kiwango cha Idadi ya Watu
\[\sigma = \sqrt{\dfrac{\sum(x-\mu)^{2}}{N}} \label{eq3} \]
au
\[\sigma = \sqrt{\dfrac{\sum f (x-\mu)^{2}}{N}} \label{eq4}\]
Kwa kupotoka kwa kiwango cha idadi ya watu, denominator ni\(N\), idadi ya vitu katika idadi ya watu.
Katika Equations\ ref {eq2} na\ ref {eq4},\(f\) inawakilisha mzunguko ambao thamani inaonekana. Kwa mfano, kama thamani inaonekana mara moja,\(f\) ni moja. Kama thamani inaonekana mara tatu katika kuweka data au idadi ya watu,\(f\) ni tatu.
Sampuli tofauti ya Takwimu
Takwimu za usambazaji wa sampuli zilijadiliwa katika Sehemu ya 2.6. Kiasi gani takwimu inatofautiana kutoka sampuli moja hadi nyingine inajulikana kama sampuli tofauti ya takwimu. Kwa kawaida hupima tofauti ya sampuli ya takwimu kwa kosa lake la kawaida.
Hitilafu ya kawaida ya maana ni mfano wa kosa la kawaida. Ni kupotoka kwa kiwango maalum na inajulikana kama kupotoka kwa kiwango cha usambazaji wa sampuli ya maana. Wewe cover makosa ya kiwango cha maana katika Sura ya 7. Uthibitisho wa kosa la kawaida la maana\(\sigma\) ni\(\dfrac{\sigma}{\sqrt{n}}\) wapi kupotoka kwa kiwango cha idadi ya watu na\(n\) ni ukubwa wa sampuli.
Katika mazoezi, TUMIA CALCULATOR AU PROGRAMU YA KOMPYUTA ILI KUHESABU KUPOTOKA Ikiwa unatumia calculator ya TI-83, 83+, 84+, unahitaji kuchagua kupotoka kwa kiwango sahihi\(\sigma_{x}\) au \(s_{x}\)kutoka kwa takwimu za muhtasari. Tutazingatia kutumia na kutafsiri habari ambazo kupotoka kwa kawaida hutupa. Hata hivyo, unapaswa kujifunza mfano wa hatua kwa hatua ili kukusaidia kuelewa jinsi kupotoka kwa kiwango kinachopunguza tofauti kutoka kwa maana. (Maelekezo ya calculator yanaonekana mwishoni mwa mfano huu.)
Mfano\(\PageIndex{1}\)
Katika darasa la daraja la tano, mwalimu alikuwa na nia ya umri wa wastani na kupotoka kwa kiwango cha sampuli ya umri wa wanafunzi wake. Takwimu zifuatazo ni umri wa sampuli ya n = 20 wanafunzi wa daraja la tano. Miaka ni mviringo kwa nusu ya karibu ya mwaka:
9; 9.5; 9.5; 10; 10; 10; 10.5; 10.5; 10.5; 10.5; 11; 11; 11; 11; 11; 11; 11; 11.5; 11.5;
\[\bar{x} = \dfrac{9+9.5(2)+10(4)+10.5(4)+11(6)+11.5(3)}{20} = 10.525 \nonumber\]
Umri wa wastani ni miaka 10.53, umezunguka sehemu mbili.
Tofauti inaweza kuhesabiwa kwa kutumia meza. Kisha kupotoka kwa kawaida kunahesabiwa kwa kuchukua mizizi ya mraba ya ugomvi. Tutaelezea sehemu za meza baada ya kuhesabu s.
| Data | Freq. | Mapungufu | Mapungufu 2 | (Freq.) (Mapungufu 2) |
|---|---|---|---|---|
| x | f | (x -\(\bar{x}\)) | (x - 2\(\bar{x}\)) | (f) (x -\(\bar{x}\)) 2 |
| 9 | 1 | 9 — 10.525 = —1.525 | (—1.525) 2 = 2.325625 | 1 × 2.325625 = 2.325625 |
| 9.5 | 2 | 9.5 — 10.525 = —1.025 | (—1.025) 2 = 1.050625 | 2 × 1.050625 = 2.101250 |
| 10 | 4 | 10 — 10.525 = —0.525 | (—0.525) 2 = 0.275625 | 4 × 0.275625 = 1.1025 |
| 10.5 | 4 | 10.5 — 10.525 = —0.025 | (—0.025) 2 = 0.000625 | 4 × 0.000625 = 0.0025 |
| 11 | 6 | 11 — 10.525 = 0.475 | (0.475) 2 = 0.225625 | 6 × 0.225625 = 1.35375 |
| 11.5 | 3 | 11.5 — 10.525 = 0.975 | (0.975) 2 = 0.950625 | 3 × 0.950625 = 2.851875 |
| Jumla ni 9.7375 |
Ubaguzi wa sampuli\(s^{2}\),, ni sawa na jumla ya safu ya mwisho (9.7375) imegawanywa na idadi ya maadili ya data chini ya moja (20 - 1):
\[s^{2} = \dfrac{9.7375}{20-1} = 0.5125 \nonumber\]
sampuli kiwango kupotoka s ni sawa na mizizi mraba ya sampuli ugomvi:
\[s = \sqrt{0.5125} = 0.715891 \nonumber\]
na hii ni mviringo kwa maeneo mawili decimal,\(s = 0.72\).
Kwa kawaida, unafanya hesabu kwa kupotoka kwa kiwango kwenye calculator yako au kompyuta. Matokeo ya kati hayajazunguka. Hii imefanywa kwa usahihi.
- Kwa matatizo yafuatayo, kumbuka kwamba thamani = maana + (#ofSTDEVs) (kiwango kupotoka). Thibitisha maana na kiwango kupotoka au calculator au kompyuta.
- Kwa sampuli:\(x\) =\(\bar{x}\) + (#ofSTDEVs) (s)
- Kwa idadi ya watu:\(x\) =\(\mu\) + (#ofSTDEVs)\(\sigma\)
- Kwa mfano huu, tumia x =\(\bar{x}\) + (#ofSTDEVs) (s) kwa sababu data inatoka kwa sampuli
- Thibitisha maana na kiwango kupotoka kwenye calculator yako au kompyuta.
- Pata thamani ambayo ni kupotoka kwa kiwango kimoja juu ya maana. Pata (\(\bar{x}\)+ 1s).
- Pata thamani ambayo ni upungufu wa kiwango cha chini chini ya maana. Kupata (\(\bar{x}\)- 2s).
- Pata maadili ambayo ni upungufu wa kiwango cha 1.5 kutoka (chini na juu) maana.
Suluhisho
-
- Orodha wazi L1 na L2. Vyombo vya habari STAT 4:ClorList. Ingiza 2 1 kwa L1, comma (,), na 2 2 kwa L2.
- Ingiza data kwenye mhariri wa orodha. Press STAT 1:HARIRI. Ikiwa ni lazima, fungua orodha kwa kuimarisha jina. Waandishi wa habari wazi na mshale chini.
- Weka maadili ya data (9, 9.5, 10, 10.5, 11, 11.5) kwenye orodha ya L1 na masafa (1, 2, 4, 4, 6, 3) kwenye orodha L2. Kutumia funguo arrow kuzunguka.
- Bonyeza STAT na mshale kwa CALC. Waandishi wa habari 1:1 -varStats na uingie L1 (2 1), L2 (2 2). Usisahau comma. Waandishi wa habari kuingia.
- \(\bar{x}\)= 10.525
- Tumia Sx kwa sababu hii ni data ya sampuli (sio idadi ya watu): Sx=0.715891
- (\(\bar{x} + 1s) = 10.53 + (1)(0.72) = 11.25\)
- \((\bar{x} - 2s) = 10.53 – (2)(0.72) = 9.09\)
-
- \((\bar{x} - 1.5s) = 10.53 – (1.5)(0.72) = 9.45\)
- \((\bar{x} + 1.5s) = 10.53 + (1.5)(0.72) = 11.61\)
Zoezi 2.8.1
Katika timu ya baseball, umri wa kila wachezaji ni kama ifuatavyo:
21; 21; 22; 23; 24; 24; 25; 25; 28; 29; 29; 31; 32; 33; 33; 34; 35; 36; 36; 36; 36; 36; 38; 38; 38; 40
Tumia calculator yako au kompyuta ili upate kupotoka kwa maana na kiwango. Kisha kupata thamani ambayo ni upungufu wa kiwango mbili juu ya maana.
Jibu
\(\mu\)= 30.68
\(s = 6.09\)
(\(\bar{x} + 2s = 30.68 + (2)(6.09) = 42.86\).
Maelezo ya hesabu ya kupotoka kwa kiwango kilichoonyeshwa kwenye meza
Ukosefu unaonyesha jinsi kuenea data ni kuhusu maana. Thamani ya data 11.5 ni mbali na maana kuliko thamani ya data 11 ambayo inaonyeshwa na upungufu 0.97 na 0.47. Kupotoka kwa chanya hutokea wakati thamani ya data ni kubwa kuliko maana, wakati kupotoka hasi hutokea wakati thamani ya data ni chini ya maana. Kupotoka ni -1.525 kwa thamani ya data tisa. Ikiwa unaongeza upungufu, jumla ni daima sifuri. (Kwa mfano\(\PageIndex{1}\), kuna\(n = 20\) uvunjaji.) Hivyo huwezi tu kuongeza deviations kupata kuenea kwa data. Kwa kuzingatia upungufu, unawafanya idadi nzuri, na jumla pia itakuwa chanya. Tofauti, basi, ni kupotoka kwa wastani wa mraba.
Tofauti ni kipimo cha mraba na hauna vitengo sawa na data. Kuchukua mizizi ya mraba hutatua tatizo. Kupotoka kwa kiwango hupima kuenea katika vitengo sawa na data.
Kumbuka kwamba badala ya kugawa na\(n = 20\), hesabu kugawanywa kwa\(n - 1 = 20 - 1 = 19\) sababu data ni sampuli. Kwa ugomvi wa sampuli, tunagawanya na ukubwa wa sampuli chini ya moja (\(n - 1\)). Kwa nini usigawanye na\(n\)? Jibu linahusiana na ugomvi wa idadi ya watu. sampuli ugomvi ni makadirio ya ugomvi idadi ya watu. Kulingana na hisabati ya kinadharia iliyo nyuma ya mahesabu haya, kugawa kwa (\(n - 1\)) kunatoa makadirio bora ya ugomvi wa idadi ya watu.
Mkusanyiko wako unapaswa kuwa juu ya kile kupotoka kwa kiwango kinatuambia kuhusu data. Kupotoka kwa kiwango ni namba ambayo inachukua umbali gani data zinaenea kutoka kwa maana. Hebu calculator au kompyuta kufanya hesabu.
Kupotoka kwa kiwango,\(s\) au\(\sigma\), ni sifuri au kubwa kuliko sifuri. Wakati kupotoka kwa kiwango ni sifuri, hakuna kuenea; yaani, maadili yote ya data yanafanana. Kupotoka kwa kiwango ni ndogo wakati data zote zimejilimbikizia karibu na maana, na ni kubwa wakati maadili ya data yanaonyesha tofauti zaidi kutoka kwa maana. Wakati kupotoka kwa kiwango ni kubwa zaidi kuliko sifuri, maadili ya data yanaenea sana kuhusu maana; outliers wanaweza kufanya\(s\) au kubwa\(\sigma\) sana.
Kupotoka kwa kawaida, wakati wa kwanza iliyotolewa, inaweza kuonekana haijulikani. Kwa kuchora data yako, unaweza kupata “kujisikia” bora kwa upungufu na kupotoka kwa kawaida. Utapata kwamba katika mgawanyo wa usawa, kupotoka kwa kawaida kunaweza kusaidia sana lakini katika mgawanyo uliopotoka, kupotoka kwa kawaida kunaweza kuwa msaada mkubwa. Sababu ni kwamba pande mbili za usambazaji wa skewed zina kuenea tofauti. Katika usambazaji uliotengwa, ni bora kuangalia robo ya kwanza, wastani, robo ya tatu, thamani ndogo zaidi, na thamani kubwa zaidi. Kwa sababu namba zinaweza kuchanganyikiwa, daima graph data yako. Onyesha data yako katika histogram au njama ya sanduku.
Mfano\(\PageIndex{2}\)
Tumia data zifuatazo (alama ya kwanza ya mtihani) kutoka darasa la Susan Dean la spring kabla ya calculus:
33; 42; 49; 49; 53; 55; 55; 61; 63; 67; 68; 68; 69; 69; 72; 73; 74; 78; 80; 83; 88; 88; 88; 90; 92; 94; 94; 94; 94; 96; 100
- Unda chati iliyo na data, masafa, masafa ya jamaa, na masafa ya jamaa ya jumla kwenye sehemu tatu za decimal.
- Tumia zifuatazo kwa sehemu moja ya decimal kwa kutumia TI-83+ au TI-84 calculator:
- Sampuli inamaanisha
- Kupotoka kwa kiwango cha sampuli
- Wastani
- Quartile ya kwanza
- Nne ya tatu
- IQR
- Jenga njama ya sanduku na histogram kwenye seti sawa ya axes. Fanya maoni kuhusu njama ya sanduku, histogram, na chati.
Jibu
- Angalia Jedwali
-
- Sampuli inamaanisha = 73.5
- Kupotoka kwa kiwango cha sampuli = 17.9
- Wastani = 73
- Quartile ya kwanza = 61
- Quartile ya tatu = 90
- IQR = 90 — 61 = 29
- \(x\)Mhimili -huenda kutoka 32.5 hadi 100.5;\(y\) -axis huenda kutoka -2.4 hadi 15 kwa histogram. Idadi ya vipindi ni tano, hivyo upana wa muda ni (\(100.5 - 32.5\)) umegawanyika na tano, ni sawa na 13.6. Mwisho wa vipindi ni kama ifuatavyo: hatua ya mwanzo ni 32.5,,\(32.5 + 13.6 = 46.1\),\(46.1 + 13.6 = 59.7\),\(59.7 + 13.6 = 73.3\)\(73.3 + 13.6 = 86.9\), thamani\(86.9 + 13.6 = 100.5 =\) ya mwisho; Hakuna maadili ya data yanaanguka kwenye mipaka ya muda.
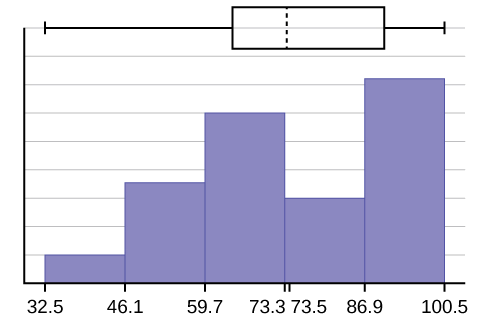
Whisker ya kushoto ya muda mrefu katika njama ya sanduku inaonekana upande wa kushoto wa histogram. kuenea kwa alama mtihani katika chini 50% ni kubwa (\(73 - 33 = 40\)) kuliko kuenea katika juu 50% (\(100 - 73 = 27\)). Histogram, njama ya sanduku, na chati zote zinaonyesha hili. Kuna idadi kubwa ya darasa A na B (80s, 90, na 100). Histogram inaonyesha wazi hii. Mpango wa sanduku unatuonyesha kuwa asilimia 50 ya alama za mtihani (IQR = 29) ni Ds, Cs, na Bs. Mpango wa sanduku pia unatuonyesha kwamba asilimia 25 ya alama za mtihani ni Ds na Fs.
| Data | Frequency | Frequency jamaa | Mzunguko wa jamaa wa Ki |
|---|---|---|---|
| 33 | 1 | 0.032 | 0.032 |
| 42 | 1 | 0.032 | 0.064 |
| 49 | 2 | 0.065 | 0.129 |
| 53 | 1 | 0.032 | 0.161 |
| 55 | 2 | 0.065 | 0.226 |
| 61 | 1 | 0.032 | 0.258 |
| 63 | 1 | 0.032 | 0.29 |
| 67 | 1 | 0.032 | 0.322 |
| 68 | 2 | 0.065 | 0.387 |
| 69 | 2 | 0.065 | 0.452 |
| 72 | 1 | 0.032 | 0.484 |
| 73 | 1 | 0.032 | 0.516 |
| 74 | 1 | 0.032 | 0.548 |
| 78 | 1 | 0.032 | 0.580 |
| 80 | 1 | 0.032 | 0.612 |
| 83 | 1 | 0.032 | 0.644 |
| 88 | 3 | 0.097 | 0.741 |
| 90 | 1 | 0.032 | 0.773 |
| 92 | 1 | 0.032 | 0.805 |
| 94 | 4 | 0.129 | 0.934 |
| 96 | 1 | 0.032 | 0.966 |
| 100 | 1 | 0.032 | 0.998 (Kwa nini thamani hii si 1?) |
Zoezi\(\PageIndex{2}\)
Takwimu zifuatazo zinaonyesha aina tofauti za maduka ya chakula cha wanyama katika eneo hilo kubeba.
6; 6; 6; 6; 7; 7; 7; 7; 7; 8; 9; 9; 9; 9; 10; 10; 10; 10; 10; 11; 11; 11; 11; 12; 12; 12; 12; 12; 12; 12; 12; 12; 12; 12;
Tumia maana ya sampuli na kupotoka kwa kiwango cha sampuli kwenye sehemu moja ya decimal kwa kutumia TI-83+ au TI-84 calculator.
Jibu
\(\mu = 9.3\)na\(s = 2.2\)
Kupotoka kwa kiwango cha Majedwali ya Makundi
Kumbuka kwamba kwa data ya makundi hatujui maadili ya data ya mtu binafsi, kwa hiyo hatuwezi kuelezea thamani ya kawaida ya data kwa usahihi. Kwa maneno mengine, hatuwezi kupata maana halisi, wastani, au mode. Tunaweza, hata hivyo, kuamua makadirio bora ya hatua za kituo kwa kutafuta maana ya data iliyowekwa na formula:
\[\text{Mean of Frequency Table} = \dfrac{\sum fm}{\sum f}\]
ambapo\(f\) muda frequency na midpoints\(m =\) muda.
Kama vile hatukuweza kupata maana halisi, wala hatuwezi kupata halisi kiwango kupotoka. Kumbuka kwamba kiwango kupotoka inaelezea numerically kupotoka inatarajiwa thamani data ina kutoka maana. Kwa Kiingereza rahisi, kupotoka kwa kawaida kunatuwezesha kulinganisha jinsi data “isiyo ya kawaida” ya mtu binafsi inalinganishwa na maana.
Mfano\(\PageIndex{3}\)
Kupata kiwango kupotoka kwa data katika Jedwali\(\PageIndex{3}\).
| Hatari | Frequency, f | Midpoint, m | m 2 | \(\bar{x}\) | fm 2 | Mkengeuko |
|---|---|---|---|---|---|---|
| 0—2 | 1 | 1 | 1 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 1 | 3.5 |
| 3—5 | 6 | 4 | 16 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 96 | 3.5 |
| 6—8 | 10 | 7 | 49 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 490 | 3.5 |
| 9—11 | 7 | 10 | 100 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 700 | 3.5 |
| 12—14 | 0 | 13 | 169 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 0 | 3.5 |
| 15—17 | 2 | 16 | 256 | \ (\ bar {x}\)” style="wima align:katikati; "> 7.58 | 512 | 3.5 |
Kwa kuweka data hii, tuna maana,\(\bar{x}\) = 7.58 na kupotoka kwa kiwango,\(s_{x}\) = 3.5. Hii ina maana kwamba thamani ya data iliyochaguliwa kwa nasibu itatarajiwa kuwa vitengo 3.5 kutoka kwa maana. Ikiwa tunaangalia darasa la kwanza, tunaona kwamba midpoint ya darasa ni sawa na moja. Hii ni karibu mbili kamili ya kiwango ukiukaji kutoka maana tangu 7.58 - 3.5 - 3.5 = 0.58. Wakati formula ya kuhesabu kupotoka kwa kawaida sio ngumu,\(s_{x} = \sqrt{\dfrac{f(m - \bar{x})^{2}}{n-1}}\) ambapo\(s_{x}\) = sampuli ya kupotoka kwa kiwango,\(\bar{x}\) = sampuli inamaanisha, mahesabu yanatisha. Kwa kawaida ni bora kutumia teknolojia wakati wa kufanya mahesabu.
Pata kupotoka kwa kiwango kwa data kutoka kwa mfano uliopita
| Hatari | 0-2 | 3-5 | 6-8 | 9—11 | 12—14 | 15—17 |
|---|---|---|---|---|---|---|
| Frequency, f | 1 | 6 | 10 | 7 | 0 | 2 |
Kwanza, bonyeza kitufe cha STAT na chagua 1:Hariri

Ingiza maadili ya midpoint ndani ya L1 na frequency ndani ya L2

Chagua STAT, CALC, na 1:1-Var Stats

Chagua 2 na kisha 1 kisha, 2 na kisha 2 Ingiza

Utaona kuonyeshwa wote idadi ya watu kiwango kupotoka,\(\sigma_{x}\), na sampuli kiwango kupotoka,\(s_{x}\).
Kulinganisha Maadili kutoka kwa seti tofauti za Data
Kupotoka kwa kawaida ni muhimu wakati wa kulinganisha maadili ya data yanayotokana na seti tofauti za data. Ikiwa seti za data zina njia tofauti na upungufu wa kawaida, kisha kulinganisha maadili ya data moja kwa moja inaweza kupotosha.
- Kwa kila thamani ya data, hesabu ngapi upungufu wa kiwango mbali na maana yake thamani ni.
- Tumia formula: thamani = maana + (#ofSTDEVs) (kupotoka kwa kawaida); tatua kwa #ofSTDEVs.
- \(\text{#ofSTDEVs} = \dfrac{\text{value-mean}}{\text{standard deviation}}\)
- Linganisha matokeo ya hesabu hii.
#ofSTDEVs mara nyingi huitwa "z -score”; tunaweza kutumia ishara\(z\). Katika alama, fomu zinakuwa:
| Sampuli | \(x = \bar{x} + zs\) | \(z = \dfrac{x - \bar{x}}{s}\) |
| Idadi ya watu | \(x = \mu + z\sigma\) | \(z = \dfrac{x - \mu}{\sigma}\) |
Mfano\(\PageIndex{4}\)
Wanafunzi wawili, John na Ali, kutoka shule mbalimbali za upili, walitaka kujua ni nani aliyekuwa na GPA ya juu zaidi ikilinganishwa na shule yake. Ni mwanafunzi gani aliyekuwa na GPA ya juu zaidi ikilinganishwa na shule yake?
| Mwanafunzi | GPA | Shule Maana GPA | Shule ya Mkengeuko |
|---|---|---|---|
| John | 2.85 | 3.0 | 0.7 |
| Ali | 77 | 80 | 10 |
Jibu
Kwa kila mwanafunzi, tambua ni kiasi gani cha kupotoka kwa kiwango (#ofSTDEVs) GPA yake iko mbali na wastani, kwa shule yake. Jihadharini na ishara wakati wa kulinganisha na kutafsiri jibu.
\[z = \text{#ofSTDEVs} = \left(\dfrac{\text{value-mean}}{\text{standard deviation}}\right) = \left(\dfrac{x + \mu}{\sigma}\right) \nonumber\]
Kwa ajili ya Yohana,
\[z = \text{#ofSTDEVs} = \left(\dfrac{2.85-3.0}{0.7}\right) = -0.21 \nonumber\]
Kwa Ali,
\[z = \text{#ofSTDEVs} = (\dfrac{77-80}{10}) = -0.3 \nonumber\]
John ana GPA bora ikilinganishwa na shule yake kwa sababu GPA yake ni 0.21 kupotoka standard chini ya maana ya shule yake wakati GPA Ali ni 0.3 kupotoka standard chini ya maana ya shule yake.
Yohana z -score ya -0.21 ni kubwa kuliko Ali z -score ya —0.3. Kwa GPA, maadili ya juu ni bora, kwa hiyo tunahitimisha kwamba John ana GPA bora ikilinganishwa na shule yake.
Zoezi\(\PageIndex{4}\)
Waogeleaji wawili, Angie na Beth, kutoka timu tofauti, walitaka kujua ni nani aliyekuwa na muda wa haraka zaidi kwa freestyle ya mita 50 ikilinganishwa na timu yake. Ambayo mwogeleaji alikuwa na muda wa haraka zaidi ikilinganishwa na timu yake?
| Mwogeleaji | Muda (sekunde) | Muda wa Maana ya Timu | Timu Standard Kupotoka |
|---|---|---|---|
| Angie | 26.2 | 27.2 | 0.8 |
| Beth | 27.3 | 30.1 | 1.4 |
Jibu
Kwa Angie:
\[z = \left(\dfrac{26.2-27.2}{0.8}\right) = -1.25 \nonumber\]
Kwa Beth:
\[z = \left(\dfrac{27.3-30.1}{1.4}\right) = -2 \nonumber\]
Orodha zifuatazo zinatoa ukweli machache ambao hutoa ufahamu zaidi kidogo katika kile kupotoka kwa kiwango kinatuambia kuhusu usambazaji wa data.
Kwa kuweka data yoyote, bila kujali usambazaji wa data ni:
- Angalau 75% ya data ni ndani ya upungufu wa kawaida wa maana.
- Angalau 89% ya data ni ndani ya upungufu wa kiwango cha tatu cha maana.
- Angalau 95% ya data ni ndani ya upungufu wa kiwango cha 4.5 cha maana.
- Hii inajulikana kama Kanuni ya Chebyshev.
Kwa data kuwa na usambazaji ambao ni BELL-UMBO na SYMMETRIC:
- Takriban 68% ya data ni ndani ya kupotoka kwa kiwango kimoja cha maana.
- Takriban 95% ya data ni ndani ya upungufu wa kawaida wa maana.
- Zaidi ya 99% ya data ni ndani ya upungufu wa kiwango cha tatu cha maana.
- Hii inajulikana kama Utawala wa kimapenzi.
- Ni muhimu kutambua kwamba sheria hii inatumika tu wakati sura ya usambazaji wa data ni umbo la kengele na linganifu. Tutajifunza zaidi kuhusu hili wakati wa kusoma usambazaji wa “Kawaida” au “Gaussia” uwezekano katika sura za baadaye.
Marejeo
- Data kutoka Microsoft Bookshelf.
- Mfalme, Bill. “Graphically akizungumza.” Taasisi Utafiti, Ziwa Tahoe Community College. Inapatikana mtandaoni kwenye www.ltcc.edu/web/about/institutional-research (kupatikana Aprili 3, 2013).
Mapitio
Kupotoka kwa kawaida kunaweza kukusaidia kuhesabu kuenea kwa data. Kuna milinganyo tofauti ya kutumia ikiwa ni kuhesabu kupotoka kwa kiwango cha sampuli au ya idadi ya watu.
- Kupotoka Standard inaruhusu sisi kulinganisha data ya mtu binafsi au madarasa kwa kuweka data maana numerically.
- \(s = \sqrt{\dfrac{\sum(x-\bar{x})^{2}}{n-1}}\)au\(s = \sqrt{\dfrac{\sum f (x-\bar{x})^{2}}{n-1}}\) ni formula ya kuhesabu kupotoka kwa kiwango cha sampuli. Kuhesabu kiwango kupotoka ya idadi ya watu, tunataka kutumia idadi ya watu maana,\(\mu\), na formula\(\sigma = \sqrt{\dfrac{\sum(x-\mu)^{2}}{N}}\) au\(\sigma = \sqrt{\dfrac{\sum f (x-\mu)^{2}}{N}}\). f (x - μ) 2 N - - - - - - - - √.
Mapitio ya Mfumo
\[s_{x} = \sqrt{\dfrac{\sum fm^{2}}{n} - \bar{x}^2}\]
wapi\(s_{x} \text{sample standard deviation}\) na\(\bar{x} = \text{sample mean}\)
Tumia maelezo yafuatayo ili kujibu mazoezi mawili yafuatayo: Data zifuatazo ni umbali kati ya maduka 20 ya rejareja na kituo kikubwa cha usambazaji. Umbali ni katika maili.
29; 37; 38; 40; 58; 67; 68; 69; 76; 86; 87; 95; 96; 96; 99; 106; 112; 127; 145; 150
Zoezi 2.8.4
Tumia calculator ya graphing au kompyuta ili kupata kupotoka kwa kiwango na pande zote hadi kumi ya karibu.
Jibu
\(s\)= 34.5
Zoezi 2.8.5
Pata thamani ambayo ni kupotoka kwa kiwango kimoja chini ya maana.
Zoezi 2.8.6
Wachezaji wawili wa baseball, Fredo na Karl, kwenye timu tofauti walitaka kujua nani alikuwa na wastani wa batting juu ikilinganishwa na timu yake. Ambayo baseball mchezaji alikuwa juu batting wastani ikilinganishwa na timu yake?
| Mchezaji wa baseball | Batting Wastani | Timu Batting Wastani | Timu Standard Kupotoka |
|---|---|---|---|
| Fredo | 0.158 | 0.166 | 0.012 |
| Karl | 0.177 | 0.189 | 0.015 |
Jibu
Kwa Fredo:
\(z\)=\(\dfrac{0.158-0.166}{0.012}\) = —0.67
Kwa Karl:
\(z\)=\(\dfrac{0.177-0.189}{0.015}\) = —0.8
Fredo ya z -score ya -0.67 ni kubwa kuliko Karl z -score ya -0.8. Kwa batting wastani, maadili ya juu ni bora, hivyo Fredo ina bora batting wastani ikilinganishwa na timu yake.
Zoezi 2.8.7
Tumia Jedwali ili kupata thamani ambayo ni upungufu wa kiwango cha tatu:
- juu ya maana
- chini ya maana
Pata kupotoka kwa kiwango kwa meza zifuatazo za mzunguko kwa kutumia formula. Angalia mahesabu na TI 83/84.
Zoezi 2.8.5
Pata kupotoka kwa kiwango kwa meza zifuatazo za mzunguko kwa kutumia formula. Angalia mahesabu na TI 83/84.
-
Daraja Frequency 49.5—59.5 2 59.5—69.5 3 69.5—79.5 8 79.5—89.5 12 89.5—99.5 5 -
Joto la chini la kila siku Frequency 49.5—59.5 53 59.5—69.5 32 69.5—79.5 15 79.5—89.5 1 89.5—99.5 0 -
Pointi kwa kila mchezo Frequency 49.5—59.5 14 59.5—69.5 32 69.5—79.5 15 79.5—89.5 23 89.5—99.5 2
Jibu
- \(s_{x} = \sqrt{\dfrac{\sum fm^{2}}{n} - \bar{x}^{2}} = \sqrt{\dfrac{193157.45}{30} - 79.5^{2}} = 10.88\)
- \(s_{x} = \sqrt{\dfrac{\sum fm^{2}}{n} - \bar{x}^{2}} = \sqrt{\dfrac{380945.3}{101} - 60.94^{2}} = 7.62\)
- \(s_{x} = \sqrt{\dfrac{\sum fm^{2}}{n} - \bar{x}^{2}} = \sqrt{\dfrac{440051.5}{86} - 70.66^{2}} = 11.14\)
Kuleta Pamoja
Zoezi 2.8.7
Wanafunzi ishirini na tano waliochaguliwa kwa nasibu waliulizwa idadi ya sinema walizoangalia wiki iliyopita. Matokeo ni kama ifuatavyo:
| # ya sinema | Frequency |
|---|---|
| 0 | 5 |
| 1 | 9 |
| 2 | 6 |
| 3 | 4 |
| 4 | 1 |
- Pata maana ya sampuli\(\bar{x}\).
- Kupata takriban sampuli kiwango kupotoka,\(s\).
Jibu
- 1.48
- 1.12
Zoezi 2.8.8
Wanafunzi arobaini waliochaguliwa kwa nasibu waliulizwa idadi ya jozi ya sneakers waliomilikiwa Hebu idadi\(X =\) ya jozi ya sneakers inayomilikiwa. Matokeo ni kama ifuatavyo:
| \(X\) | Mzunguko y |
|---|---|
| \ (X\) ">1 | 2 |
| \ (X\) "> 2 | 5 |
| \ (X\) ">3 | 8 |
| \ (X\) ">4 | 12 |
| \ (X\) "> 5 | 12 |
| \ (X\) ">6 | 0 |
| \ (X\) ">7 | 1 |
- Pata maana ya sampuli\(\bar{x}\)
- Kupata sampuli kiwango kupotoka, s
- Kujenga histogram ya data.
- Jaza nguzo za chati.
- Pata robo ya kwanza.
- Pata wastani.
- Pata robo ya tatu.
- Jenga njama ya sanduku ya data.
- Ni asilimia gani ya wanafunzi inayomilikiwa angalau jozi tano?
- Kupata 40 th percentile.
- Kupata 90 th percentile.
- Jenga grafu ya mstari wa data
- Jenga stemplot ya data
Zoezi 2.8.9
Zifuatazo ni uzito kuchapishwa (katika paundi) wote wa wanachama wa timu ya San Francisco 49ers kutoka mwaka uliopita.
177; 205; 210; 210; 232; 205; 185; 185; 178; 210; 206; 212; 184; 174; 185; 242; 188; 212; 215; 241; 223; 220; 260; 245; 259; 278; 270; 295; 275; 290; 272; 273; 280; 285; 286; 200; 215; 185; 230; 250; 241; 190; 260; 250; 302; 265; 290; 276; 228; 265
- Panga data kutoka ndogo hadi thamani kubwa.
- Pata wastani.
- Pata robo ya kwanza.
- Pata robo ya tatu.
- Jenga njama ya sanduku ya data.
- Katikati ya 50% ya uzito ni kutoka _______ hadi _______.
- Ikiwa idadi yetu walikuwa wachezaji wote wa mpira wa miguu wa kitaaluma, ingekuwa data hapo juu itakuwa sampuli ya uzito au idadi ya uzito? Kwa nini?
- Kama idadi ya watu wetu ni pamoja na kila mwanachama wa timu ambaye milele alicheza kwa San Francisco 49ers, bila data hapo juu kuwa sampuli ya uzito au idadi ya watu wa uzito? Kwa nini?
- Kudhani idadi ya watu ilikuwa San Francisco 49ers. Kupata:
- idadi ya watu ina maana,\(\mu\).
- idadi ya watu kiwango kupotoka,\(\sigma\).
- uzito kwamba ni mbili deviations kiwango chini ya maana.
- Wakati Steve Young, quarterback, alicheza mpira wa miguu, alipima paundi 205. Ni kiasi gani cha kupotoka kwa kiwango juu au chini ya maana alikuwa yeye?
- Mwaka huo huo, uzito wa maana kwa Dallas Cowboys ulikuwa paundi 240.08 na kupotoka kwa kiwango cha paundi 44.38. Emmit Smith vunja katika saa 209 paundi. Kwa heshima na timu yake, ambaye alikuwa nyepesi, Smith au Young? Uliamua jinsi gani jibu lako?
Jibu
- 174; 177; 178; 184; 185; 185; 185; 185; 188; 190; 200; 205; 205; 206; 210; 210; 210; 212; 215; 215; 220; 223; 228; 230; 232; 241; 241; 242; 245; 245; 250; 259; 260; 260; 265; 270; 273; 273; 276; 278; 280; 285; 285; 286; 290; 290; 295; 302
- 241
- 205.5
- 272.5

- 205.5, 272.5
- sampuli
- idadi
-
- 236.34
- 37.50
- 161.34
- 0.84 std. dev. chini ya maana
- Young
Zoezi 2.8.10
Walimu mia moja walihudhuria semina ya kutatua matatizo ya hisabati. Mitazamo ya sampuli ya mwakilishi wa 12 ya walimu ilipimwa kabla na baada ya semina. Nambari nzuri ya mabadiliko katika mtazamo inaonyesha kwamba mtazamo wa mwalimu kuelekea hesabu ulikuwa chanya zaidi. The 12 mabadiliko alama ni kama ifuatavyo:
3; 8; —1; 2; 0; 5; -3; 1; -1; 6; 5; -2
- ni maana ya mabadiliko ya alama gani?
- Je, ni kupotoka kwa kiwango gani kwa idadi hii?
- Je, ni alama ya mabadiliko ya wastani?
- Pata alama ya mabadiliko ambayo ni 2.2 kiwango cha kupotoka chini ya maana.
Zoezi 2.8.11
Rejea Kielelezo kuamua ni ipi kati ya yafuatayo ni ya kweli na ambayo ni ya uongo. Eleza ufumbuzi wako kwa kila sehemu katika sentensi kamili.
<figure >

</figure>
- Wafanyabiashara wa grafu zote tatu ni sawa.
- Hatuwezi kuamua kama njia yoyote ya grafu tatu ni tofauti.
- Kupotoka kwa kiwango cha grafu b ni kubwa kuliko kupotoka kwa kawaida kwa grafu a.
- Hatuwezi kuamua kama yoyote ya robo ya tatu kwa grafu tatu ni tofauti.
Jibu
- Kweli
- Kweli
- Kweli
- Uongo
Zoezi 2.8.12
Katika suala la hivi karibuni la Spectrum ya IEEE, mikutano ya uhandisi 84 ilitangazwa. Mikutano minne ilidumu siku mbili. Thelathini na sita ilidumu siku tatu. Kumi na nane ilidumu siku nne. Kumi na tisa ilidumu siku tano. Nne ilidumu siku sita. Moja ilidumu siku saba. Moja ilidumu siku nane. Moja ilidumu siku tisa. Hebu X = urefu (katika siku) ya mkutano wa uhandisi.
- Panga data katika chati.
- Pata wastani, robo ya kwanza, na robo ya tatu.
- Kupata 65 th percentile.
- Kupata 10 th percentile.
- Jenga njama ya sanduku ya data.
- Katikati ya 50% ya mikutano ya mwisho kutoka siku _______ hadi siku _______.
- Tumia maana ya sampuli ya siku za mikutano ya uhandisi.
- Tumia sampuli ya kiwango cha kupotoka kwa siku za mikutano ya uhandisi.
- Pata mode.
- Ikiwa ungepanga mkutano wa uhandisi, ungependa kuchagua kama urefu wa mkutano: maana; wastani; au mode? Eleza kwa nini ulifanya uchaguzi huo.
- Kutoa sababu mbili kwa nini unafikiri kwamba siku tatu hadi tano zinaonekana kuwa urefu maarufu wa mikutano ya uhandisi.
Zoezi 2.8.13
Utafiti wa uandikishaji katika vyuo 35 vya jamii nchini Marekani ulitoa takwimu zifuatazo:
6414; 1550; 2109; 9350; 21828; 4300; 5944; 5722; 2825; 2044; 5481; 5200; 5853; 2750; 10012; 6357; 27000; 9414; 7681; 3200; 17500; 9200; 7380; 18314; 6557; 13713; 17768; 7493; 2771; 2861; 1263; 7285; 28165; 5080; 11622
- Panga data kwenye chati na vipindi vitano vya upana sawa. Weka safu mbili “Uandikishaji” na “Frequency.”
- Kujenga histogram ya data.
- Ikiwa ungekuwa na kujenga chuo kipya cha jamii, ni kipande gani cha habari kitakuwa cha thamani zaidi: mode au maana?
- Tumia maana ya sampuli.
- Tumia sampuli ya kupotoka kwa kiwango.
- Shule yenye uandikishaji wa 8000 itakuwa ni kiasi gani cha kupotoka kwa kiwango mbali na maana?
Jibu
-
Uandikishaji Frequency 1000-5000 10 5000-10000 16 10000-15000 3 15000-20000 3 20000-25000 1 25000-30000 2 - Angalia ufumbuzi wa mwanafunzi.
- mtindo
- 8628.74
- 6943.88
- —0.09
Tumia maelezo yafuatayo ili kujibu mazoezi mawili yafuatayo. \(X =\)idadi ya siku kwa wiki ambayo wateja 100 hutumia kituo cha zoezi fulani.
| \(x\) | Frequency |
|---|---|
| \ (x\) "> 0 | 3 |
| \ (x\) ">1 | 12 |
| \ (x\) "> 2 | 33 |
| \ (x\) ">3 | 28 |
| \ (x\) ">4 | 11 |
| \ (x\) "> 5 | 9 |
| \ (x\) ">6 | 4 |
Zoezi 2.8.14
Asilimia ya 80 ni _____
- 5
- 80
- 3
- 4
Zoezi 2.8.15
Nambari ambayo ni upungufu wa kiwango cha 1.5 CHINI ya maana ni takriban _____
- 0.7
- 4.8
- —2.8
- Haiwezi kuamua
Jibu
a
Zoezi 2.8.16
Tuseme kwamba mchapishaji alifanya utafiti kuuliza watumiaji wazima idadi ya vitabu vya uongo Paperback walikuwa kununuliwa katika mwezi uliopita. Matokeo ni muhtasari katika Jedwali.
| # ya vitabu | Freq. | Reel. Freq. |
|---|---|---|
| 0 | 18 | |
| 1 | 24 | |
| 2 | 24 | |
| 3 | 22 | |
| 4 | 15 | |
| 5 | 10 | |
| 7 | 5 | |
| 9 | 1 |
- Je, kuna nje yoyote katika data? Tumia mtihani sahihi wa nambari unaohusisha IQR kutambua nje, ikiwa kuna, na ueleze wazi hitimisho lako.
- Ikiwa thamani ya data inatambuliwa kama nje, ni nini kifanyike kuhusu hilo?
- Je, data yoyote inakadiriwa zaidi ya kupotoka kwa kiwango mbili mbali na maana? Katika hali fulani, wanatakwimu wanaweza kutumia vigezo hivi kutambua maadili ya data ambayo ni ya kawaida, ikilinganishwa na maadili mengine ya data. (Kumbuka kuwa vigezo hivi ni sahihi zaidi kutumia kwa data ambayo ni umbo la mlima na linganifu, badala ya data iliyopigwa.)
- Je, sehemu a na c ya tatizo hili hutoa jibu sawa?
- Kuchunguza sura ya data. Ni sehemu gani, a au c, ya swali hili inatoa matokeo sahihi zaidi kwa data hii?
- Kulingana na sura ya data ambayo ni kipimo sahihi zaidi ya kituo cha data hii: maana, wastani au mode?
faharasa
- Mkengeuko
- idadi ambayo ni sawa na mizizi mraba ya ugomvi na hatua jinsi mbali data maadili ni kutoka maana yao; notation: s kwa sampuli kupotoka kiwango na σ kwa idadi ya watu kiwango kupotoka.
Wachangiaji na Majina
- Uchanganisho
- maana ya kupotoka kwa mraba kutoka kwa maana, au mraba wa kupotoka kwa kiwango; kwa seti ya data, kupotoka kunaweza kuwakilishwa kama \(x\)—\(\bar{x}\) wapi\(x\) thamani ya data na\(\bar{x}\) ni maana ya sampuli. Tofauti ya sampuli ni sawa na jumla ya mraba wa upungufu uliogawanywa na tofauti ya ukubwa wa sampuli na moja.