
10.5: Sampuli zinazofanana au zilizounganishwa
- Page ID
- 181224

Wakati wa kutumia mtihani wa hypothesis kwa sampuli zinazofanana au zilizounganishwa, sifa zifuatazo zinapaswa kuwepo:
- Rahisi sampuli random hutumiwa.
- Ukubwa wa sampuli mara nyingi ni ndogo.
- Vipimo viwili (sampuli) vinatokana na jozi moja ya watu binafsi au vitu.
- Tofauti ni mahesabu kutoka sampuli kuendana au paired.
- Tofauti huunda sampuli ambayo hutumiwa kwa mtihani wa hypothesis.
- Aidha jozi zinazoendana zina tofauti zinazotokana na idadi ya watu ambayo ni ya kawaida au idadi ya tofauti ni kubwa ya kutosha ili usambazaji wa sampuli maana ya tofauti ni takriban kawaida.
Katika mtihani wa hypothesis kwa sampuli zinazofanana au zilizounganishwa, masomo yanafanana na jozi na tofauti huhesabiwa. Tofauti ni data. idadi ya watu maana kwa tofauti,\(\mu_{d}\), ni kisha kupimwa kwa kutumia Mwanafunzi\(t\) -mtihani kwa idadi ya watu moja maana na\(n - 1\) digrii ya uhuru, ambapo\(n\) ni idadi ya tofauti.
Takwimu za mtihani (\(t\)-score) ni:
\[t = \dfrac{\bar{x}_{d} - \mu_{d}}{\left(\dfrac{s_{d}}{\sqrt{n}}\right)}\]
Mfano\(\PageIndex{1}\)
Utafiti ulifanyika kuchunguza ufanisi wa hypnotism katika kupunguza maumivu. Matokeo ya masomo yaliyochaguliwa kwa nasibu yanaonyeshwa kwenye Jedwali. Alama ya chini inaonyesha maumivu kidogo. Thamani “kabla” inafanana na thamani ya “baada” na tofauti zinahesabiwa. Tofauti zina usambazaji wa kawaida. Je, vipimo vya hisia, kwa wastani, chini baada ya hypnotism? Mtihani kwa kiwango cha umuhimu wa 5%.
| Somo: | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| Kabla ya | 6.6 | 6.5 | 9.0 | 10.3 | 11.3 | 8.1 | 6.3 | 11.6 |
| Baada ya | 6.8 | 2.4 | 7.4 | 8.5 | 8.1 | 6.1 | 3.4 | 2.0 |
Jibu
Sambamba “kabla” na “baada ya” maadili huunda jozi zinazofanana. (Mahesabu “baada ya” — “kabla.”)
| Baada ya Data | Kabla ya Data | Tofauti |
|---|---|---|
| 6.8 | 6.6 | 0.2 |
| 2.4 | 6.5 | -4.1 |
| 7.4 | 9 | -1.6 |
| 8.5 | 10.3 | -1.8 |
| 8.1 | 11.3 | -3.2 |
| 6.1 | 8.1 | -2 |
| 3.4 | 6.3 | -2.9 |
| 2 | 11.6 | -9.6 |
Takwimu za mtihani ni tofauti:\(\{0.2, -4.1, -1.6, -1.8, -3.2, -2, -2.9, -9.6\}\)
sampuli maana na sampuli kiwango kupotoka ya tofauti ni:\(\bar{x}_{d} = -3.13\) na\(s_{d} = 2.91\) Thibitisha maadili haya.
Hebu\(\mu_{d}\) kuwa idadi ya watu ina maana ya tofauti. Tunatumia dd ya usajili ili kutaja “tofauti.”
Tofauti ya random:
\(\bar{X}_{d} =\)tofauti ya maana ya vipimo vya hisia
\[H_{0}: \mu_{d} \geq 0\]
Nadharia tete null ni sifuri au chanya, maana yake ni kwamba kuna maumivu sawa au zaidi waliona baada ya hypnotism. Hiyo ina maana somo inaonyesha hakuna uboreshaji. \(\mu_{d}\)ni maana ya idadi ya watu ya tofauti.
\[H_{a}: \mu_{d} < 0\]
hypothesis mbadala ni hasi, maana kuna maumivu kidogo waliona baada ya hypnotism. Hiyo ina maana somo inaonyesha kuboresha. Alama inapaswa kuwa ya chini baada ya hypnotism, hivyo tofauti inapaswa kuwa hasi ili kuonyesha uboreshaji.
Usambazaji kwa mtihani:
usambazaji ni t Mwanafunzi na\(df = n - 1 = 8 - 1 = 7\). Tumia\(t_{7}\). (Taarifa kwamba mtihani ni kwa ajili ya idadi ya watu moja maana.)
Tumia thamani ya p kwa kutumia usambazaji wa Mwanafunzi-t:
\[p\text{-value} = 0.0095\]
Grafu:
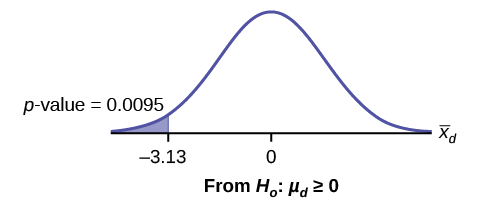
\(\bar{X}_{d}\)ni variable random kwa tofauti.
Sampuli ina maana na sampuli ya kupotoka kwa kiwango cha tofauti ni:
\(\bar{x}_{d} = -3.13\)
\(s_{d} = 2.91\)
Linganisha\(\alpha\) na\(p\text{-value}\)
\(\alpha = 0.05\)na\(p\text{-value} = 0.0095\). \(\alpha > p\text{-value}\)
Kufanya uamuzi
tangu\(\alpha > p\text{-value}\), kukataa\(H_{0}\). Hii ina maana kwamba\(\mu_{d} < 0\) na kuna kuboresha.
Hitimisho
Katika kiwango cha 5% cha umuhimu, kutoka kwa data ya sampuli, kuna ushahidi wa kutosha ili kuhitimisha kuwa vipimo vya hisia, kwa wastani, ni vya chini baada ya hypnotism. Hypnotism inaonekana kuwa na ufanisi katika kupunguza maumivu.
Kwa calculators TI-83+ na TI-84, unaweza ama kuhesabu tofauti kabla ya muda (baada - kabla) na kuweka tofauti katika orodha au unaweza kuweka data baada katika orodha ya kwanza na data kabla katika orodha ya pili. Kisha nenda kwenye orodha ya tatu na mshale hadi jina. Ingiza jina la orodha ya 1 - jina la orodha ya 2 nd. Calculator itafanya uondoaji, na utakuwa na tofauti katika orodha ya tatu.
Tumia orodha yako ya tofauti kama data. Bonyeza STAT na mshale juu ya vipimo. Vyombo vya habari 2:T-mtihani. Mshale juu ya Data na waandishi wa habari kuingia. Arrow chini na kuingia 0 kwa\(\mu_{0}\), jina la orodha ambapo kuweka data, na 1 kwa Freq:. Mshale chini hadi \(\mu\): na mshale juu ya \(\mu_{0}\)<. Bonyeza kuingia. Mshale chini kwa Hesabu na waandishi wa habari kuingia. Ya\(p\text{-value}\) ni 0.0094, na takwimu za mtihani ni -3.04. Je, maelekezo haya tena isipokuwa, mshale kuteka (badala ya Mahesabu). Bonyeza kuingia.
Zoezi\(\PageIndex{1}\)
Utafiti ulifanyika kuchunguza jinsi ufanisi wa chakula kipya ulivyokuwa katika kupunguza cholesterol. Matokeo ya masomo yaliyochaguliwa kwa nasibu yanaonyeshwa kwenye meza. Tofauti zina usambazaji wa kawaida. Je, viwango vya cholesterol vya masomo hupungua kwa wastani baada ya chakula? Mtihani katika kiwango cha 5%.
| Subject | A | B | C | D | E | F | G | H | Mimi |
|---|---|---|---|---|---|---|---|---|---|
| Kabla ya | 209 | 210 | 205 | 198 | 216 | 217 | 238 | 240 | 222 |
| Baada ya | 199 | 207 | 189 | 209 | 217 | 202 | 211 | 223 | 201 |
Jibu
Ya\(p\text{-value}\) ni 0.0130, hivyo tunaweza kukataa hypothesis null. Kuna ushahidi wa kutosha wa kupendekeza kwamba chakula hupunguza cholesterol.
Mfano\(\PageIndex{2}\)
Kocha wa soka wa chuo hicho alikuwa na nia ya kama darasa la maendeleo ya nguvu la chuo liliongeza kiwango cha juu cha kuinua wachezaji wake (kwa paundi) kwenye zoezi la vyombo vya habari vya benchi. Aliuliza wachezaji wake wanne kushiriki katika utafiti. Kiasi cha uzito walichoweza kuinua kila kilirekodiwa kabla ya kuchukua darasa la maendeleo ya nguvu. Baada ya kukamilisha darasa, kiasi cha uzito walichoweza kuinua kila kilipimwa tena. Takwimu ni kama ifuatavyo:
| Uzito (kwa paundi) | Mchezaji 1 | Mchezaji 2 | Mchezaji 3 | Mchezaji 4 |
|---|---|---|---|---|
| Kiasi cha uzito kilichoinuliwa kabla ya darasa | 205 | 241 | 338 | 368 |
| Kiasi cha uzito kilichoinuliwa baada ya darasa | 295 | 252 | 330 | 360 |
Kocha anataka kujua kama darasa la maendeleo ya nguvu hufanya wachezaji wake kuwa na nguvu, kwa wastani.
Rekodi data tofauti. Tumia tofauti kwa kuondoa kiasi cha uzito kilichoinuliwa kabla ya darasa kutoka kwa uzito ulioinuliwa baada ya kukamilisha darasa. Takwimu za tofauti ni:\(\{90, 11, -8, -8\}\). Fikiria tofauti zina usambazaji wa kawaida.Kutumia data tofauti, tumia mahesabu ya sampuli na kupotoka kwa kiwango cha sampuli.
\[\bar{x}_{d} = 21.3\]
na
\[s_{d} = 46.7\]
Takwimu zilizotolewa hapa zinaonyesha kwamba usambazaji ni kweli wa kulia. tofauti 90 inaweza kuwa outlier uliokithiri? Ni kuunganisha sampuli maana ya kuwa 21.3 (chanya). Njia za maadili mengine matatu ya data ni kweli hasi.
Kutumia data tofauti, hii inakuwa mtihani wa __________ moja (kujaza tupu).
Kufafanua variable random:\(\bar{X}\) maana tofauti katika kuinua kiwango cha juu kwa mchezaji.
Usambazaji wa mtihani wa hypothesis ni\(t_{3}\).
- \(H_{0}: \mu_{d} \leq 0\),
- \(H_{a}: \mu_{d} > 0\)
Grafu:
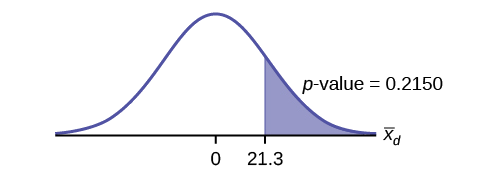
Mahesabu ya\(p\text{-value}\):\(p\text{-value}\) ni 0.2150
Suluhisho: Kama kiwango cha umuhimu ni 5%, uamuzi si kukataa hypothesis null, kwa sababu\(\alpha < p\text{-value}\).
Hitimisho ni nini?
Katika kiwango cha 5% cha umuhimu, kutoka kwa data ya sampuli, hakuna ushahidi wa kutosha wa kuhitimisha kuwa darasa la maendeleo ya nguvu lilisaidia kufanya wachezaji kuwa na nguvu, kwa wastani.
Zoezi\(\PageIndex{2}\)
mpya prep darasa iliundwa kuboresha SAT alama mtihani. Wanafunzi watano walichaguliwa kwa random. Alama zao kwenye mitihani miwili ya mazoezi yalirekodiwa, moja kabla ya darasa na moja baada ya. Data iliyoandikwa katika Jedwali. Je, alama, kwa wastani, za juu baada ya darasa? Mtihani kwa kiwango cha 5%.
| SAT alama | Mwanafunzi 1 | Mwanafunzi 2 | Mwanafunzi 3 | Mwanafunzi 4 |
|---|---|---|---|---|
| Alama kabla ya darasa | 1840 | 1960 | 1920 | 2150 |
| Alama baada ya darasa | 1920 | 2160 | 2200 | 2100 |
Jibu
Ya\(p\text{-value}\) ni 0.0874, hivyo sisi kushuka kukataa hypothesis null. data wala msaada kwamba darasa inaboresha SAT alama kwa kiasi kikubwa.
Mfano\(\PageIndex{3}\)
Wafanyabiashara saba wa nane katika Shule ya Kennedy Middle walipima umbali gani wanaweza kushinikiza risasi-kuweka kwa mkono wao mkubwa (kuandika) na mkono wao dhaifu (usio wa kuandika). Walidhani kwamba wanaweza kushinikiza umbali sawa na mkono wowote. Takwimu zilikusanywa na kurekodi katika Jedwali.
| Umbali (kwa miguu) kutumia | Mwanafunzi 1 | Mwanafunzi 2 | Mwanafunzi 3 | Mwanafunzi 4 | Mwanafunzi 5 | Mwanafunzi 6 | Mwanafunzi 7 |
|---|---|---|---|---|---|---|---|
| mkono kubwa | 30 | 26 | 34 | 17 | 19 | 26 | 20 |
| mkono dhaifu | 28 | 14 | 27 | 18 | 17 | 26 | 16 |
Kufanya mtihani wa hypothesis kuamua kama tofauti ya maana katika umbali kati ya mikono kubwa ya watoto dhidi ya mikono dhaifu ni muhimu.
Rekodi data tofauti. Tumia tofauti kwa kuondoa umbali na mkono dhaifu kutoka umbali na mkono mkubwa. Takwimu za tofauti ni:\(\{2, 12, 7, –1, 2, 0, 4\}\). Tofauti zina usambazaji wa kawaida.
Kutumia data tofauti, tumia mahesabu ya sampuli na kupotoka kwa kiwango cha sampuli. \(\bar{x} = 3.71\),\(s_{d} = 4.5\).
Tofauti ya random:\(\bar{X} =\) maana tofauti katika umbali kati ya mikono.
Usambazaji kwa mtihani wa hypothesis:\(t_{6}\)
\(H_{0}: \mu_{d} = 0 H_{a}: \mu_{d} \neq 0\)
Grafu:
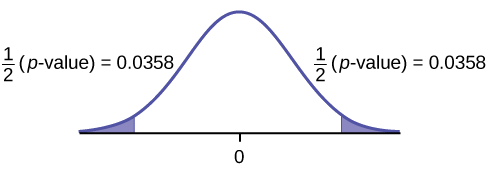
Tumia p -thamani:\(p\text{-value}\) ni 0.0716 (kutumia data moja kwa moja).
(mtihani wa takwimu = 2.18. \(p\text{-value} = 0.0719\)kutumia\((\bar{x}_{d} = 3.71, s_{d} = 4.5\).
Uamuzi: kudhani\(\alpha = 0.05\). tangu\(\alpha < p\text{-value}\), Je, si kukataa\(H_{0}\).
Hitimisho: Katika kiwango cha 5% cha umuhimu, kutoka kwa data ya sampuli, hakuna ushahidi wa kutosha wa kuhitimisha kuwa kuna tofauti katika mikono dhaifu na ya juu ya watoto kushinikiza risasi-kuweka.
Zoezi\(\PageIndex{3}\)
Wachezaji wa mpira watano wanafikiri wanaweza kutupa umbali sawa na mkono wao mkubwa (kutupa) na off-mkono (kuambukizwa mkono). Takwimu zilikusanywa na kurekodi katika Jedwali. Kufanya mtihani wa hypothesis kuamua kama tofauti ya maana katika umbali kati ya mkono mkubwa na wa mbali ni muhimu. Mtihani katika kiwango cha 5%.
| Mchezaji 1 | Mchezaji 2 | Mchezaji 3 | Mchezaji 4 | Mchezaji 5 | |
|---|---|---|---|---|---|
| mkono kubwa | 120 | 111 | 135 | 140 | 125 |
| Off-mkono | 105 | 109 | 98 | 111 | 99 |
Jibu
Ya\(p\text{-level}\) ni 0.0230, hivyo tunaweza kukataa hypothesis null. Takwimu zinaonyesha kwamba wachezaji hawapati umbali sawa na mikono yao mbali kama wanavyofanya kwa mikono yao kubwa.
Tathmini
mtihani hypothesis kwa sampuli kuendana au paired (t-mtihani) ina sifa hizi:
- Jaribu tofauti kwa kuondoa kipimo kimoja kutoka kwa kipimo kingine
- Random Variable:\(x_{d} =\) maana ya tofauti
- Distribution: Mwanafunzi t-usambazaji na\(n - 1\) digrii ya uhuru
- Ikiwa idadi ya tofauti ni ndogo (chini ya 30), tofauti lazima zifuate usambazaji wa kawaida.
- Sampuli mbili zinatokana na seti sawa ya vitu.
- Sampuli ni tegemezi.
Mapitio ya Mfumo
Takwimu za mtihani (t -score):\[t = \dfrac{\bar{x}_{d}}{\left(\dfrac{s_{d}}{\sqrt{n}}\right)}\]
ambapo:
\(x_{d}\)ni maana ya tofauti za sampuli. \(\mu_{d}\)ni maana ya tofauti ya idadi ya watu. \(s_{d}\)ni sampuli kiwango kupotoka ya tofauti. \(n\)ni ukubwa wa sampuli.