
11.4:蛋白质合成(翻译)
- Page ID
- 200130

学习目标
- 描述遗传密码并解释为什么它被认为几乎是普遍的
- 解释翻译过程和翻译分子机制的功能
- 比较真核生物和原核生物的翻译
蛋白质的合成比任何其他代谢过程消耗更多的细胞能量。 反过来,蛋白质占活生物体中任何其他大分子的质量都要大。 它们几乎发挥细胞的所有功能,既是功能元素(例如酶)又是结构元素。 翻译或蛋白质合成过程是基因表达的第二部分,涉及核糖体将 mRNA 信息解码为多肽产物。
遗传密码
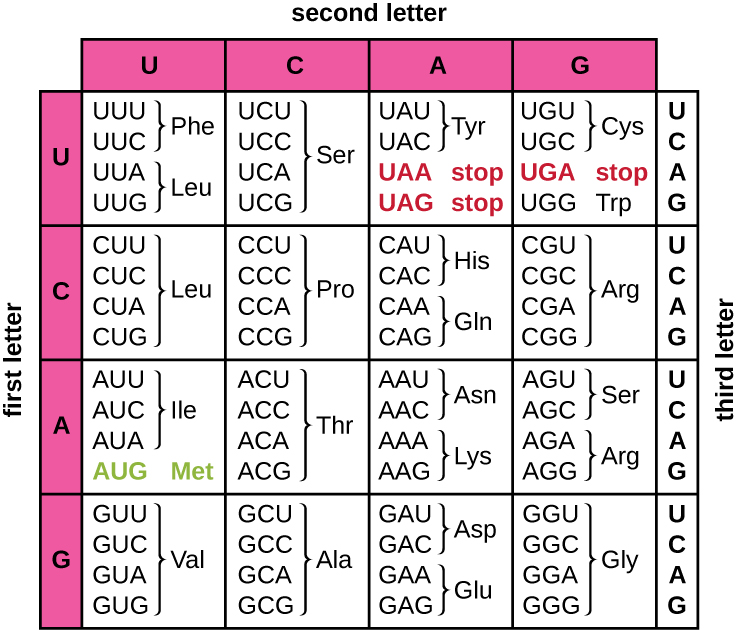
mRNA 模板的翻译将基于核苷酸的遗传信息转化为氨基酸的 “语言”,从而产生蛋白质产物。 蛋白质序列由 20 种常见的氨基酸组成。 每种氨基酸在 mRNA 中都由称为密码子的三重核苷酸定义。 mRNA 密码子与其对应的氨基酸之间的关系称为遗传密码。
三核苷酸密码意味着总共有64种可能的组合(4 3,密码子中三个不同位置的每个位置都有四种不同的核苷酸)。 这个数字大于氨基酸的数量,并且给定的氨基酸由多个密码子编码(图\(\PageIndex{1}\))。 遗传密码中的这种冗余被称为退化。 通常,密码子中的前两个位置对于确定哪种氨基酸将被掺入生长中的多肽很重要,而第三个位置称为摆动位置,则不那么重要。 在某些情况下,如果第三位的核苷酸发生变化,则仍会掺入相同的氨基酸。
尽管64个可能的三胞胎中有61个编码氨基酸,而64个密码子中有3个不编码氨基酸;它们终止蛋白质合成,将多肽从翻译机制中释放出来。 这些被称为停止密码子或废话密码子。 另一个密码子 AUG 也有一个特殊的功能。 除了指定氨基酸甲硫氨酸外,它通常还用作启动翻译的起始密码子。 读取框架,即 mRNA 中的核苷酸分组为密码子的方式,用于翻译,由 AUG 起始密码子在 mRNA 5' 末端附近设定。 此起始密码子之后的每组三个核苷酸都是 mRNA 信息中的密码子。
遗传密码几乎是普遍的。 除了少数例外,几乎所有物种都使用相同的遗传密码进行蛋白质合成,这有力地证明了地球上所有现存生命都有共同的起源。 但是,在古细菌和细菌中已经观察到不寻常的氨基酸,例如硒半胱氨酸和吡咯赖氨酸。 就硒半胱氨酸而言,使用的密码子是UGA(通常是终止密码子)。 但是,UGA 可以使用茎环结构(称为硒半胱氨酸插入序列或 SECIS 元素)编码硒半胱氨酸,该结构位于 mRNA 的 3' 未翻译区域。 吡咯赖氨酸使用不同的停止密码子 UAG。 吡咯赖氨酸的加入需要 pyLS 基因和具有 CUA 抗密码子的独特转移 RNA (tRNA)。
练习\(\PageIndex{1}\)
- 每个密码子中有多少个碱基?
- 密码子AAU编码的是什么氨基酸?
- 当到达停止密码子时会发生什么?
蛋白质合成机械
除了 mRNA 模板外,许多分子和大分子也参与了翻译过程。 每种成分的组成因分类单元而异;例如,核糖体可能由不同数量的核糖体 RNA(rRNA)和多肽组成,具体取决于生物体。 但是,从细菌到人体细胞,蛋白质合成机制的一般结构和功能是可比的。 翻译需要输入 mRNA 模板、核糖体、tRNA 和各种酶促因子。
核糖体
核糖体是一种复杂的大分子,由催化 rRNA(称为核酶)和结构 rRNA 以及许多不同的多肽组成。 成熟的 rRNA 约占每个核糖体的50%。 原核生物有 70S 的核糖体,而真核生物在细胞质和粗糙的内质网中有 80 年代的核糖体,线粒体和叶绿体中有 70 年代的核糖体。 当核糖体不合成蛋白质时,它们会分解成大亚基和小亚单位,并在翻译开始时重新结合。 在大肠杆菌中,小亚基被描述为30S(包含16S rRNA亚基),大亚基为50S(包含5S和23S rRNA亚基),总共为70S(Svedberg单位不是累加单位)。 真核生物核糖体有一个小的40S亚单位(包含18S rRNA亚基)和一个大型的60S亚单位(包含5S、5.8S和28S rRNA亚基),总共为80年代。 小亚基负责结合 mRNA 模板,而大亚基结合 tRNA(将在下一小节中讨论)。
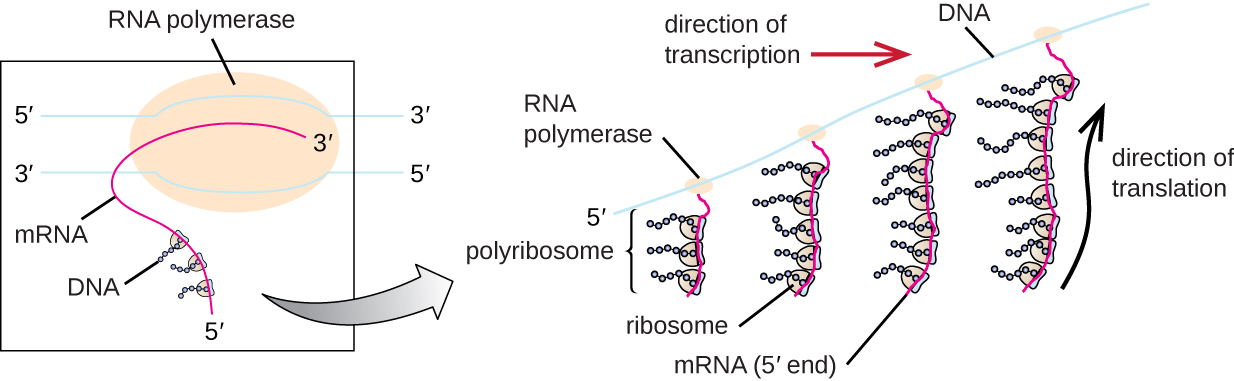
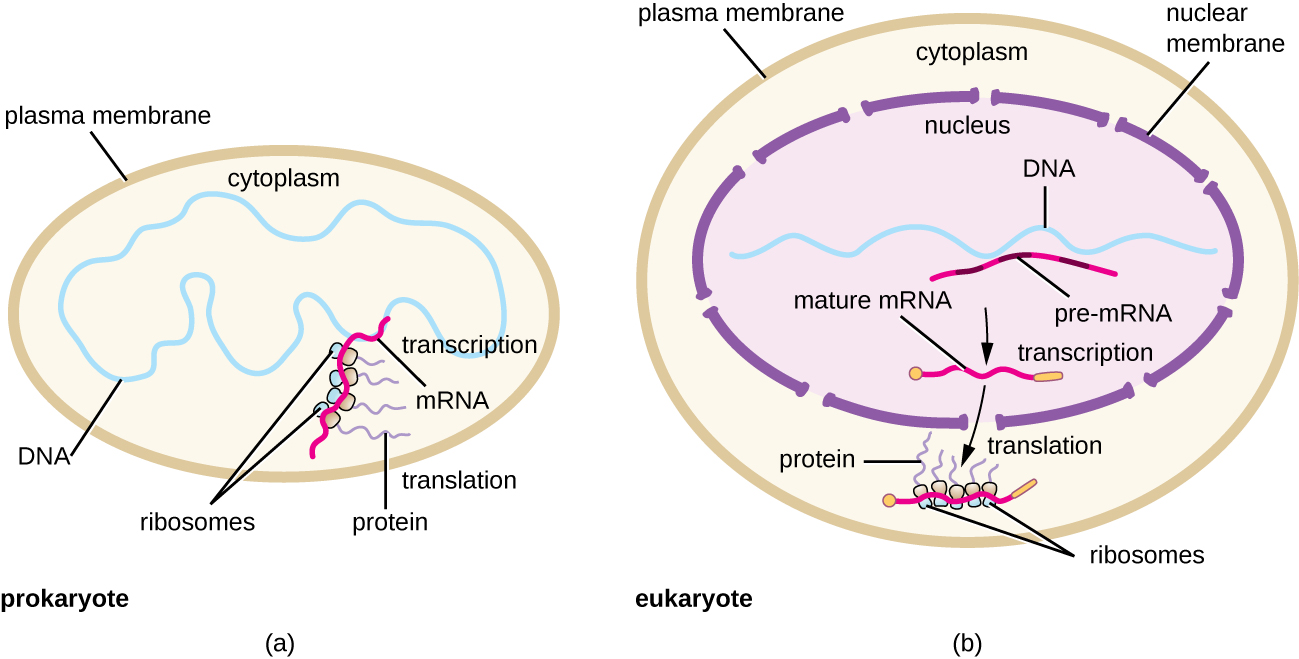
每个 mRNA 分子都由许多核糖体同时翻译,所有核糖体都朝着相同的方向合成蛋白质:从 5' 读取 mRNA 到 3',然后将多肽从 N 末端合成到 C 末端。 包含 mRNA 和多个相关核糖体的完整结构称为多核糖体(或多体)。 在细菌和古细菌中,在转录终止之前,每个蛋白质编码转录本已经被用来开始合成大量编码多肽拷贝,因为转录和翻译过程可以同时发生,形成多核糖体(图\(\PageIndex{2}\))。 转录和翻译之所以可以同时发生,是因为这两个过程都发生在相同的 5' 到 3' 方向上,它们都发生在细胞的细胞质中,也因为 RNA 转录一经转录就不会被处理。 这使原核细胞能够非常迅速地对需要新蛋白质的环境信号做出反应。 相比之下,在真核细胞中,不可能同时转录和翻译。 尽管多核糖体也会在真核生物中形成,但在 RNA 合成完成、RNA 分子被修饰并运出细胞核之前,它们无法生成。
转移 RNA
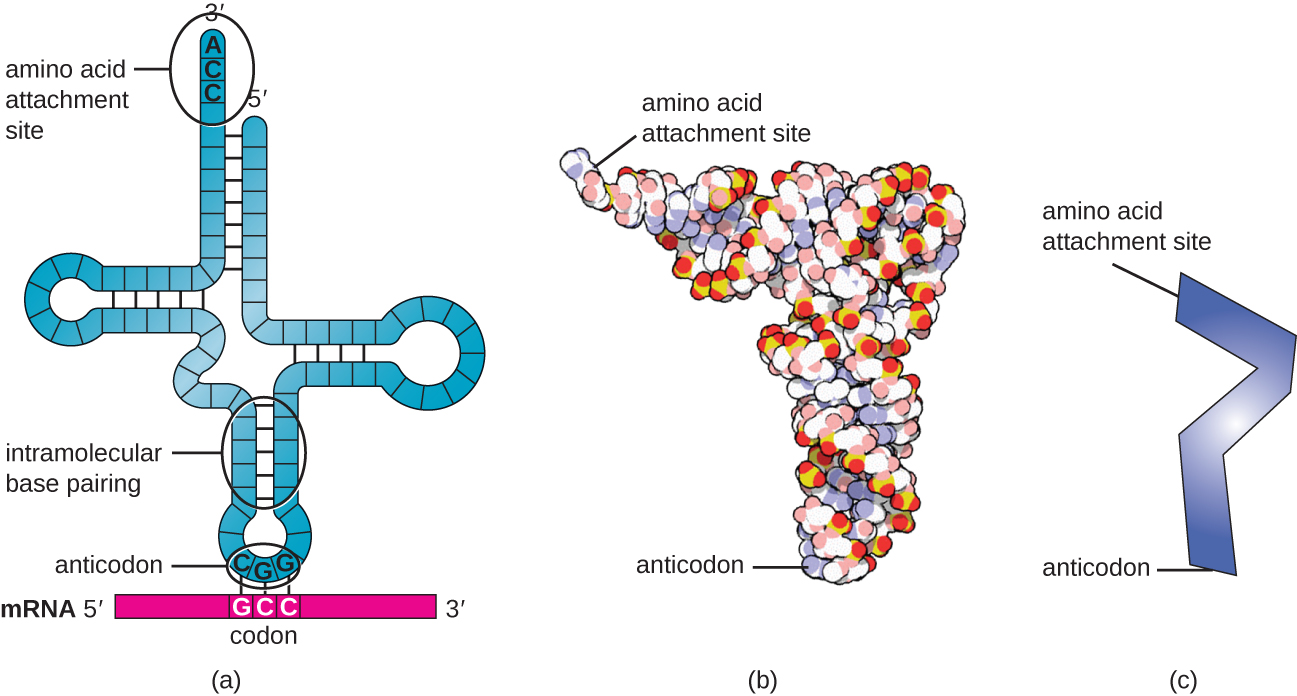
转移 RNA(tRNA)是结构化的 RNA 分子,根据物种的不同,细胞质中存在许多不同类型的 tRNA。 细菌种通常有 60 到 90 种类型。 作为适配器,每种 tRNA 类型都与 mRNA 模板上的特定密码子结合,并将相应的氨基酸添加到多肽链中。 因此,tRNA实际上是将RNA语言 “转化” 为蛋白质语言的分子。 作为翻译的适配分子,令人惊讶的是,tRNA能够在如此小的封装中具有如此高的特异性。 tRNA 分子与三个因素相互作用:氨酰基 tRNA 合成酶、核糖体和 mRNA。
当单链 RNA 分子氢键中的互补碱基相互暴露时,成熟的 tRNA 呈现出三维结构(图\(\PageIndex{3}\))。 这种形状将氨基酸结合位点定位在 tRNA 的 3' 末端,称为 CCA 氨基酸结合端,这是胞嘧啶-胞嘧啶-腺嘌呤序列,另一端是抗密码子。 抗密码子是一种三核苷酸序列,通过互补碱基配对与 mRNA 密码子结合。
通过 tRNA “充电” 过程将氨基酸添加到 tRNA 分子的末端,在此期间,每个 tRNA 分子通过一组称为氨酰基 tRNA 合成酶的酶与其正确的或同源氨基酸相连。 20 种氨基酸中每一种都至少存在一种氨基酰基 tRNA 合成酶。 在此过程中,氨基酸首先通过添加一磷酸腺苷(AMP)被激活,然后转移到 tRNA,使其成为带电的 tRNA,然后释放 AMP。
练习\(\PageIndex{2}\)
- 描述原核生物核糖体的结构和组成。
- mRNA 模板是朝哪个方向读取的?
- 描述 tRNA 的结构和功能。
蛋白质合成的机制
原核生物和真核生物的翻译类似。 在这里,我们将探讨代表性原核生物大肠杆菌的翻译是如何发生的,并具体说明细菌翻译和真核翻译之间的任何区别。
启动
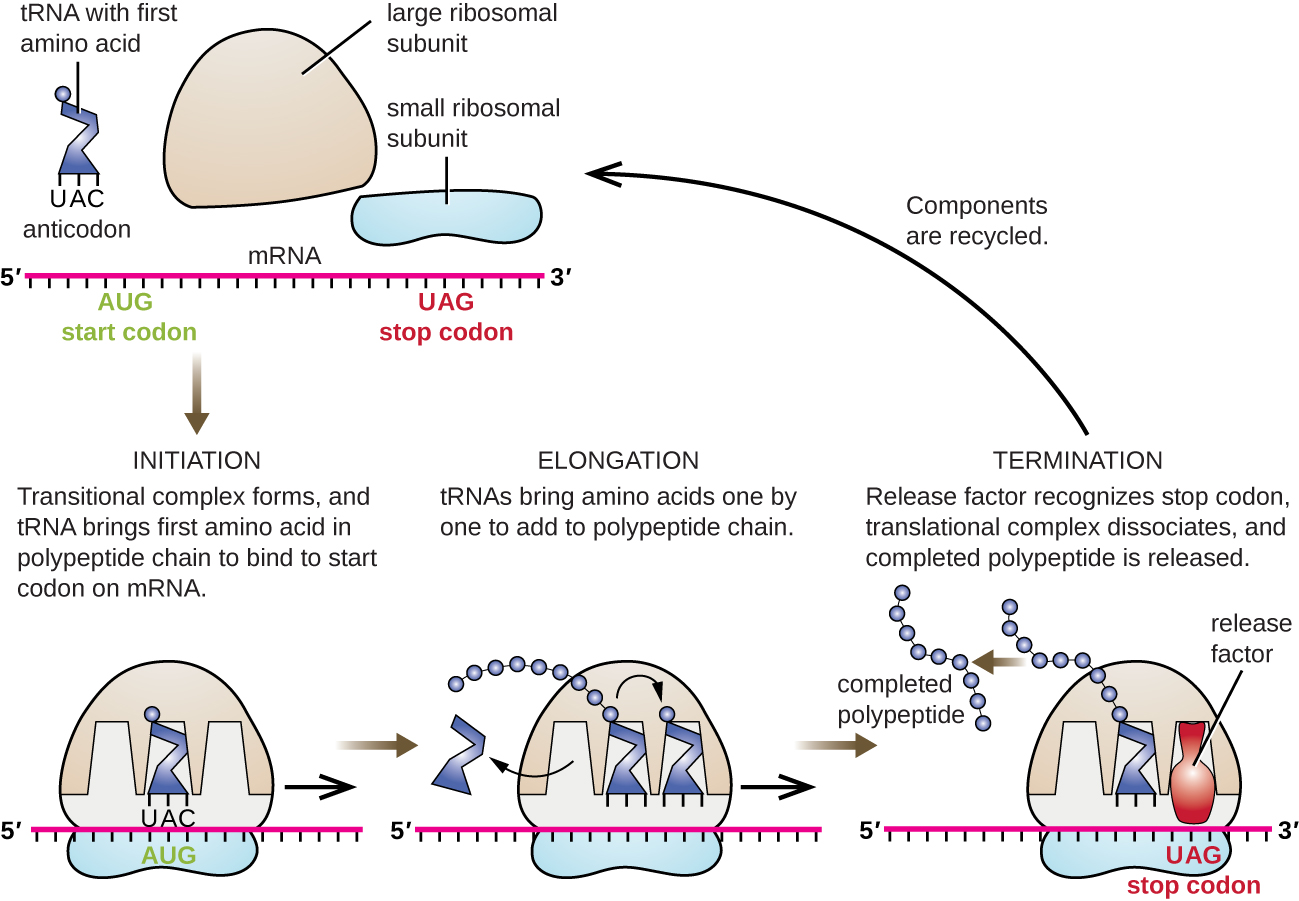
蛋白质合成的开始始于起始复合物的形成。 在大肠杆菌中,这种复合物涉及小型 30S 核糖体、mRNA 模板、三个帮助核糖体正确组装的起始因子、充当能量源的三磷酸鸟苷(GTP)和携带 N-formyl-甲硫氨酸(fmet-trna fmet)的特殊引发剂)(图\(\PageIndex{4}\))。 引发剂 tRNA 与 mRNA 的起始密码子 AUG 相互作用并携带甲酰化蛋氨酸 (fMet)。 由于 fMet 参与启动,它被插入到大肠杆菌合成的每条多肽链的开头(N 端)。 在大肠杆菌中,第一个AUG密码子上游的领导序列称为Shine-Dalgarno序列(也称为核糖体结合位点AGGAGG),通过互补碱基配对与构成核糖体的rRNA分子相互作用。 这种相互作用将 30S 核糖体亚基固定在 mRNA 模板上的正确位置。 此时,50S 核糖体亚基随后与起始复合物结合,形成完整的核糖体。
在真核生物中,起始复合物的形成是相似的,但有以下区别:
- 引发剂 tRNA 是另一种携带蛋氨酸的专用 tRNA,称为 met-trNAi
- 真核生物起始复合物不是在 Shine-Dalgarno 序列上与 mRNA 结合,而是识别真核生物 mRNA 的 5' 上限,然后沿着 5' 到 3' 方向跟踪 mRNA,直到 AUG 起始密码子被识别。 此时,60 年代亚基与 met-trNAi、mRNA 和 40S 亚单位的复合物结合。
伸长率
在原核生物和真核生物中,平移伸长的基础是相同的。 在大肠杆菌中,50S核糖体亚单位结合产生完整的核糖体形成三个功能上重要的核糖体位点:A(氨酰基)位点结合传入的带电氨酰基tRNA。 P(peptidyl)位点结合携带氨基酸的带电的 tRNA,这些氨基酸已与生长中的多肽链形成肽键,但尚未与相应的 tRNA 分离。 E(出口)位点释放分离的 tRNA,这样它们就可以被游离氨基酸充电。 这条 tRNA 装配线有一个明显的例外:在起始复合物形成过程中,细菌 fmet−trNA fmet 或真核生物 met-trnai 无需先进入 A 位点即可直接进入 P 位点,从而提供一个免费的 A 位点,准备接受与之后的第一个密码子对应的 tRNA八月
伸长是通过核糖体的单密码子运动进行的,每种运动都称为易位事件。 在每次移位事件中,带电的 tRNA 进入 A 位点,然后转移到 P 位点,最后移至 E 位点进行移除。 核糖体运动或步长是由构象变化引起的,构象变化使核糖体向 3' 方向推进三个碱基。 肽键在附着于 A 位点 tRNA 的氨基酸的氨基基和附着在 p 位点 tRNA 上的氨基酸的羧基之间形成。 每个肽键的形成都是由 peptidyl 转移酶催化的,peptidyl 转移酶是一种基于 RNA 的核酶,已整合到 50 年代核糖体亚基中。 与 p 位点 tRNA 结合的氨基酸也与不断增长的多肽链相关。 当核糖体穿过 mRNA 时,以前的 p 位点 tRNA 进入 E 位点,脱离氨基酸,然后被排出。 伸长过程中的几个步骤,包括将带电的氨酰基tRNA与A位点结合和易位,都需要来自GTP水解的能量,而GTP水解是由特定的伸长因子催化的。 令人惊讶的是,大肠杆菌翻译设备添加每种氨基酸仅需0.05秒,这意味着200 个氨基酸蛋白可以在短短 10 秒钟内转换。
终止
当遇到没有补充 tRNA 的无意义密码子(UAA、UAG 或 UGA)时,就会终止翻译。 在与 A 位点对齐时,这些无意义的密码子会被原核生物和真核生物中的释放因子识别,这些释放因子会导致 p 位点氨基酸从其 tRNA 中分离,释放出新产生的多肽。 小型和大型核糖体亚基与 mRNA 分离,相互分离;它们几乎立即被招募到另一个翻译初始化复合体中。
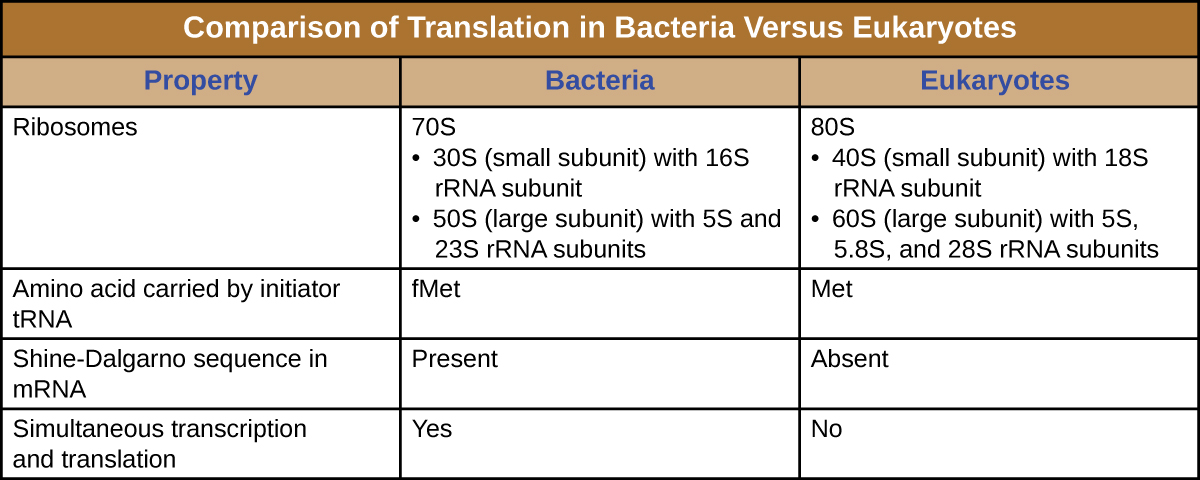
总而言之,有几个关键特征可以将原核生物的基因表达与真核生物中的表达区分开来。 它们如图所示,\(\PageIndex{5}\)并在图中列出\(\PageIndex{6}\)。
蛋白质靶向、折叠和修饰
在翻译期间和翻译之后,多肽可能需要在具有生物活性之前进行修改。 翻译后修饰包括:
- 去除翻译后的信号序列——氨基酸的短尾巴,有助于将蛋白质引导到特定的细胞隔室
- 适当 “折叠” 多肽并将多个多肽亚单位(通常由伴侣蛋白促成)结合成独特的三维结构
- 对非活性多肽进行蛋白水解处理以释放活性蛋白成分,以及
- 单个氨基酸的各种化学修饰(例如磷酸化、甲基化或糖基化)。
练习\(\PageIndex{3}\)
- 用于在原核生物中翻译的起始复合物有哪些成分?
- 启动原核生物和真核翻译有哪两个区别?
- 核糖体的三个活性位点会发生什么?
- 什么原因导致翻译终止?
关键概念和摘要
- 在翻译中,多肽是使用 mRNA 序列和细胞机制合成的,包括将 mRNA 密码子与特定氨基酸相匹配的 tRNA 和由催化反应的 RNA 和蛋白质组成的核糖体。
- 遗传密码是退化的,因为几个 mRNA 密码子编码相同的氨基酸。 遗传密码在活生物体中几乎是普遍的。
- 原核生物(70S)和细胞质真核生物(80S)核糖体分别由两组之间大小不同的大亚基和小亚基组成。 每个亚单位由 rRNA 和蛋白质组成。 真核细胞中的细胞器核糖体类似于原核生物核糖体。
- 细菌中存在大约 60 到 90 种的 tRNA。 每个 tRNA 都有一个三核苷酸抗密码子以及一个同源氨基酸的结合位点。 所有具有特定抗密码子的 tRNA 都将携带相同的氨基酸。
- 当小核糖体亚单位在 mRNA 的起@@ 始密码子处与起始因子和引发剂 tRNA 结合,然后与大型核糖体亚单位的起始复合物结合时,就会开始翻译。
- 在原核细胞中,起始密码子编码由特殊引发剂 tRNA 携带的 N-甲酰甲硫氨酸。 在真核细胞中,起始密码子编码由特殊引发剂 tRNA 携带的蛋氨酸。 此外,虽然mRNA中的Shine-Dalgarno序列促进了原核生物中mRNA的核糖体结合,但真核生物核糖体与mRNA的5'帽结合。
- 在翻译的伸长阶段,带电的 tRNA 与核糖体 A 位点中的 mRNA 结合;两个相邻的氨基酸之间催化肽键,打破第一个氨基酸与其 tRNA 之间的键;核糖体沿着核糖体 A 位点移动一个密码子mRNA;第一个 tRNA 从核糖体的 P 位点转移到 E 位点并离开核糖体复合物。
- 当核糖体遇到不编码 tRNA 的停止密码子时,就会@@ 终止翻译。 释放因子导致多肽被释放,核糖体复合物分离。
- 在原核生物中,转录和翻译可以结合在一起,在转录终止之前,只要转录允许足够的 mRNA 暴露以与核糖体结合,mRNA 分子就会开始翻译。 在真核生物中,转录和翻译不是偶联的,因为转录发生在细胞核中,而翻译发生在细胞质中或与粗糙的内质网有关。
- 多肽通常需要进行一次或多次翻译后修饰才能具有生物活性。