
4.4: डेटाबेस डिज़ाइन करना
- Page ID
- 169583
डेटाबेस डिज़ाइन करना
मान लीजिए कि एक विश्वविद्यालय छात्र क्लबों में भागीदारी को ट्रैक करने के लिए एक डेटाबेस बनाना चाहता है। कई लोगों का साक्षात्कार करने के बाद, डिज़ाइन टीम को पता चलता है कि सिस्टम को लागू करना इस बारे में बेहतर जानकारी देना है कि विश्वविद्यालय क्लब कैसे फंड करता है। यह ट्रैक करके पूरा किया जाएगा कि प्रत्येक क्लब के कितने सदस्य हैं और क्लब कितने सक्रिय हैं। टीम तय करती है कि सिस्टम को क्लब, उनके सदस्यों और उनके कार्यक्रमों पर नज़र रखनी चाहिए। इस जानकारी का उपयोग करते हुए, डिज़ाइन टीम यह निर्धारित करती है कि निम्नलिखित तालिकाओं को बनाने की आवश्यकता है:
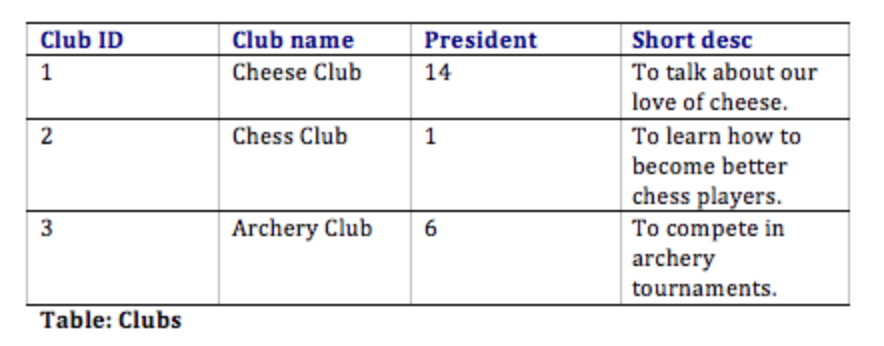
- क्लब: यह क्लब के नाम, क्लब के अध्यक्ष और क्लब के संक्षिप्त विवरण को ट्रैक करेगा।
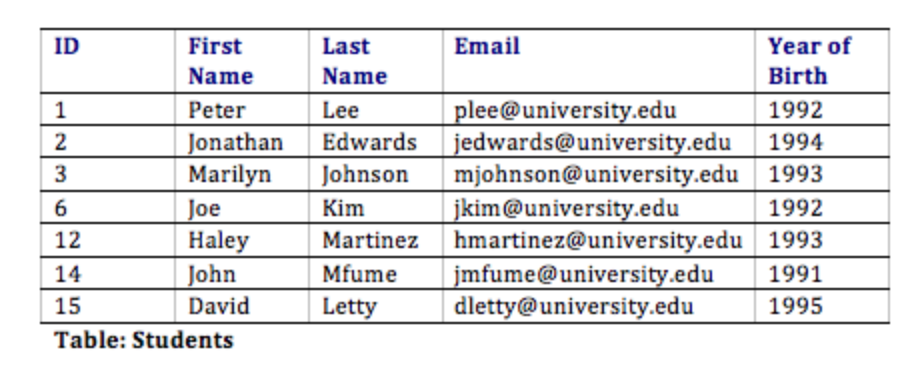
- छात्र: छात्र का नाम, ई-मेल, और जन्म का वर्ष।
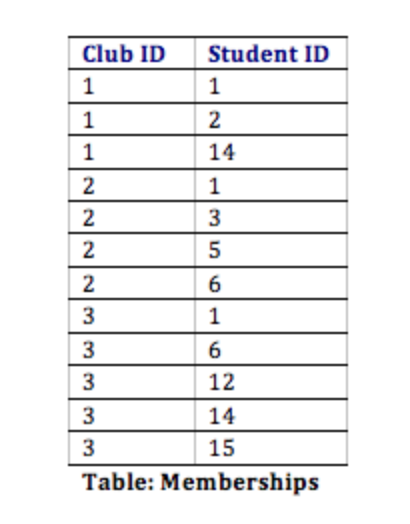
- सदस्यता: यह तालिका छात्रों को क्लब के साथ सहसंबंधित करेगी, जिससे हमें किसी भी छात्र को कई क्लबों में शामिल होने की अनुमति मिलेगी।
- कार्यक्रम: यह तालिका ट्रैक करेगी कि क्लब कब मिलेंगे और कितने छात्रों ने दिखाया।
अब जब डिज़ाइन टीम ने निर्धारित किया है कि कौन सी टेबल बनानी हैं, तो उन्हें उस विशिष्ट जानकारी को परिभाषित करने की आवश्यकता है जो प्रत्येक तालिका में होगी। इसके लिए उन फ़ील्ड की पहचान करना आवश्यक है जो प्रत्येक तालिका में होंगे। उदाहरण के लिए, क्लब का नाम क्लब टेबल के फ़ील्ड में से एक होगा। पहला नाम और अंतिम नाम स्टूडेंट्स टेबल में फ़ील्ड होगा। अंत में, चूंकि यह एक रिलेशनल डेटाबेस होगा, इसलिए प्रत्येक तालिका में कम से कम एक अन्य तालिका के साथ एक फ़ील्ड होना चाहिए (दूसरे शब्दों में: उनका एक दूसरे के साथ संबंध होना चाहिए)।
इस संबंध को ठीक से बनाने के लिए, प्रत्येक तालिका के लिए एक प्राथमिक कुंजी का चयन किया जाना चाहिए। यह कुंजी तालिका में प्रत्येक रिकॉर्ड के लिए एक विशिष्ट पहचानकर्ता है। उदाहरण के लिए, छात्र तालिका में, छात्रों के पहले नामों को विशिष्ट रूप से पहचानने के लिए उनका उपयोग करना संभव हो सकता है। हालांकि, यह संभावना से अधिक है कि कुछ छात्र अंतिम नाम (जैसे माइक, स्टेफनी, या क्रिस) साझा करेंगे, इसलिए एक अलग क्षेत्र का चयन किया जाना चाहिए। किसी छात्र का ईमेल पता प्राथमिक कुंजी के लिए एक अच्छा विकल्प हो सकता है क्योंकि ई-मेल पते अद्वितीय होते हैं। हालाँकि, एक प्राथमिक कुंजी नहीं बदल सकती है, इसलिए इसका अर्थ यह होगा कि यदि छात्रों ने अपने ईमेल पते बदल दिए हैं, तो हमें उन्हें डेटाबेस से निकालना होगा और फिर उन्हें फिर से सम्मिलित करना होगा - आकर्षक प्रस्ताव नहीं। हमारा समाधान प्रत्येक छात्र के लिए एक मूल्य बनाना है - एक उपयोगकर्ता आईडी - जो प्राथमिक कुंजी के रूप में कार्य करेगा। हम प्रत्येक छात्र क्लब के लिए भी ऐसा करेंगे। यह समाधान काफी सामान्य है और यही कारण है कि आपके पास बहुत सारे उपयोगकर्ता आईडी हैं!
आप नीचे दिए गए चित्र में अंतिम डेटाबेस डिज़ाइन देख सकते हैं:
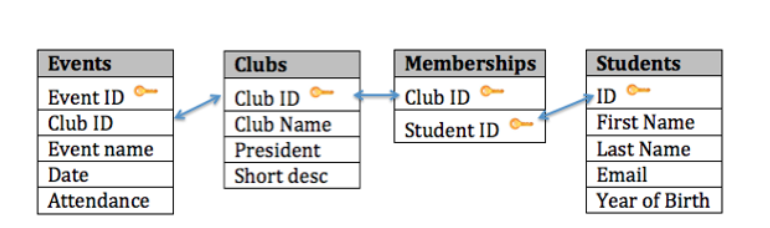
इस डिज़ाइन के साथ, न केवल हमारे पास आवश्यकताओं को पूरा करने के लिए आवश्यक सभी सूचनाओं को व्यवस्थित करने का एक तरीका है, बल्कि हमने सभी तालिकाओं को एक साथ सफलतापूर्वक संबंधित भी किया है। यहां बताया गया है कि डेटाबेस टेबल कुछ नमूना डेटा के साथ कैसा दिख सकता है। ध्यान दें कि सदस्यता तालिका का एकमात्र उद्देश्य है जिससे हम कई छात्रों को कई क्लबों से जोड़ सकते हैं।
सामान्यीकरण
डेटाबेस को डिज़ाइन करते समय, समझने के लिए एक महत्वपूर्ण अवधारणा सामान्यीकरण है। सरल शब्दों में, डेटाबेस को सामान्य करने का अर्थ है इसे इस तरह से डिज़ाइन करना कि:
- तालिकाओं के बीच डेटा की अतिरेक को कम करता है, आसान मैपिंग करता है
- असंगत डेटा निकालता है।
- जानकारी केवल एक ही स्थान पर संग्रहीत की जाती है।
- तालिका को जितना संभव हो उतना लचीलापन देता है।
स्टूडेंट क्लब डेटाबेस डिज़ाइन में, डिज़ाइन टीम ने इन उद्देश्यों को प्राप्त करने के लिए काम किया। उदाहरण के लिए, सदस्यता ट्रैक करने के लिए, क्लब टेबल में सदस्य फ़ील्ड बनाने और फिर सदस्यों के सभी नामों को सूचीबद्ध करने का एक सरल समाधान हो सकता है। हालांकि, इस डिज़ाइन का अर्थ यह होगा कि यदि कोई छात्र दो क्लब में शामिल होता है, तो उसकी जानकारी दूसरी बार दर्ज करनी होगी। इसके बजाय, डिजाइनरों ने दो तालिकाओं का उपयोग करके इस समस्या को हल किया: छात्र और सदस्यता।
इस डिज़ाइन में, जब कोई छात्र अपने पहले क्लब में शामिल होता है, तो हमें छात्र तालिका में छात्र को जोड़ना होगा, जहाँ उनका पहला नाम, अंतिम नाम, ई-मेल पता और जन्म वर्ष दर्ज किया जाता है। स्टूडेंट्स टेबल में यह अतिरिक्त एक स्टूडेंट आईडी जेनरेट करेगा। अब हम यह दर्शाने के लिए एक नई प्रविष्टि जोड़ेंगे कि छात्र एक विशिष्ट क्लब सदस्य है। यह सदस्यता तालिका में छात्र आईडी और क्लब आईडी के साथ एक रिकॉर्ड जोड़कर पूरा किया जाता है। यदि यह छात्र दूसरे क्लब में शामिल होता है, तो हमें छात्र के नाम, ई-मेल और जन्म वर्ष की नकल करने की आवश्यकता नहीं है; इसके बजाय, हमें केवल दूसरे क्लब की आईडी और छात्र की आईडी की सदस्यता तालिका में एक और प्रविष्टि करने की आवश्यकता है।
स्टूडेंट क्लब डेटाबेस डिज़ाइन मौजूदा संरचना में बड़े संशोधनों के बिना डिज़ाइन को बदलना भी आसान बनाता है। उदाहरण के लिए, यदि डिज़ाइन टीम को क्लब में संकाय सलाहकारों को ट्रैक करने के लिए सिस्टम में कार्यक्षमता जोड़ने के लिए कहा गया था, तो हम संकाय सलाहकार तालिका (छात्र तालिका के समान) जोड़कर और फिर संकाय सलाहकार आईडी रखने के लिए क्लब टेबल में एक नया फ़ील्ड जोड़कर इसे आसानी से पूरा कर सकते हैं।
डेटा के प्रकार
डेटाबेस तालिका में फ़ील्ड को परिभाषित करते समय, हमें प्रत्येक फ़ील्ड को एक डेटा प्रकार देना होगा। उदाहरण के लिए, फ़ील्ड बर्थ ईयर एक वर्ष है, इसलिए यह एक संख्या होगी, जबकि पहला नाम टेक्स्ट होगा। अधिकांश आधुनिक डेटाबेस कई अलग-अलग डेटा प्रकारों को संग्रहीत करने की अनुमति देते हैं। अधिक सामान्य डेटा प्रकारों में से कुछ यहाँ सूचीबद्ध हैं:
- पाठ: गैर-संख्यात्मक डेटा संग्रहीत करने के लिए जो संक्षिप्त है, आमतौर पर 256 वर्णों के तहत। डेटाबेस डिज़ाइनर टेक्स्ट की अधिकतम लंबाई की पहचान कर सकता है।
- संख्या: नंबर संग्रहीत करने के लिए। आमतौर पर कुछ अलग-अलग संख्या के प्रकार चुने जाते हैं, जो इस बात पर निर्भर करता है कि सबसे बड़ी संख्या कितनी बड़ी होगी।
- हां/नहीं: नंबर डेटा प्रकार का एक विशेष रूप जो (आमतौर पर) एक बाइट लंबा होता है, जिसमें “नहीं” या “गलत” के लिए 0 और “हां” या “ट्रू” के लिए 1 होता है।
- दिनांक/समय: संख्या डेटा प्रकार का एक विशेष रूप एक संख्या या एक समय के रूप में व्याख्या किया जा सकता है।
- मुद्रा: संख्या डेटा प्रकार का एक विशेष रूप जो मुद्रा संकेतक और दो दशमलव स्थानों के साथ सभी मानों को प्रारूपित करता है।
- अनुच्छेद पाठ: यह डेटा प्रकार 256 वर्णों से अधिक लंबे पाठ के लिए अनुमति देता है।
- ऑब्जेक्ट: यह डेटा प्रकार डेटा संग्रहण के लिए अनुमति देता है जिसे कीबोर्ड के माध्यम से दर्ज नहीं किया जा सकता है, जैसे कि छवि या संगीत फ़ाइल।
डेटा प्रकार को ठीक से परिभाषित करने का महत्व डेटा की अखंडता और उचित भंडारण स्थान को बेहतर बनाना है। हमें फ़ील्ड के डेटा प्रकार को ठीक से परिभाषित करना चाहिए, और एक डेटा प्रकार डेटाबेस को बताता है कि डेटा के साथ कौन से फ़ंक्शन किए जा सकते हैं। उदाहरण के लिए, यदि हम किसी एक फ़ील्ड के साथ गणितीय कार्य करना चाहते हैं, तो हमें डेटाबेस को बताना होगा कि फ़ील्ड एक संख्या डेटा प्रकार है। इसलिए यदि हमारे पास जन्म वर्ष का भंडारण करने वाला क्षेत्र है, तो हम उम्र पाने के लिए चालू वर्ष से उस क्षेत्र में संग्रहीत संख्या को घटा सकते हैं।
परिभाषित डेटा के लिए संग्रहण स्थान के आवंटन की भी पहचान की जानी चाहिए। उदाहरण के लिए, यदि प्रथम नाम फ़ील्ड को पाठ (50) डेटा प्रकार के रूप में परिभाषित किया गया है, तो प्रत्येक पहले नाम के लिए पचास वर्ण आवंटित किए जाते हैं जिन्हें हम संग्रहीत करना चाहते हैं। हालांकि, भले ही पहला नाम केवल पांच वर्ण लंबा हो, पचास वर्ण (बाइट) आवंटित किए जाएंगे। हालांकि यह एक बड़ी बात नहीं लग सकती है, अगर हमारी तालिका में 50,000 नाम हैं, तो हम इन मानों के भंडारण के लिए 50 * 50,000 = 2,500,000 बाइट आवंटित करते हैं। फ़ील्ड के आकार को कम करना विवेकपूर्ण हो सकता है, इसलिए हम भंडारण स्थान को बर्बाद नहीं करते हैं।