
4.2: डेटा के उदाहरण
- Page ID
- 169617
डेटा कुछ भी हो सकता है। डेटा के कुछ उदाहरण हैं वजन, मूल्य, लागत, बेची गई वस्तुओं की संख्या, नाम, स्थान। लगभग सभी सॉफ़्टवेयर प्रोग्रामों को कुछ उपयोगी करने के लिए डेटा की आवश्यकता होती है। यह किसी स्थान, व्यक्ति या संख्या के नाम के रूप में सीधा हो सकता है। एक उदाहरण Microsoft Word जैसे वर्ड प्रोसेसर में एक दस्तावेज़ को संपादित करना होगा, जिस दस्तावेज़ पर आप काम कर रहे हैं वह डेटा है। वर्ड-प्रोसेसिंग सॉफ़्टवेयर डेटा में हेरफेर कर सकता है: एक नया दस्तावेज़ बनाएं, एक दस्तावेज़ डुप्लिकेट करें, या दस्तावेज़ को संशोधित करें। आज हमारे पास एक नए प्रकार का डेटा है जिसे बायोमेट्रिक्स कहा जाता है, जो भौतिक या व्यवहारिक मानवीय विशेषताएं हैं जो किसी व्यक्ति को डिजिटल रूप से पहचान सकती हैं। उदाहरण पासपोर्ट के लिए चेहरे की पहचान का उपयोग किया जाएगा। फ़िंगरप्रिंट प्रमाणीकरण का उपयोग स्मार्टफ़ोन अनलॉक करने के लिए किया जाता है। आइरिस की पहचान आईरिस की उच्च-रिज़ॉल्यूशन वाली छवियों का उपयोग करती है। यह डेटा भविष्य की पहचान के लिए संग्रहीत किया जाता है। कई सरकारें और उच्च सुरक्षा कंपनियां आईरिस मान्यता का उपयोग करती हैं क्योंकि व्यक्तियों की पहचान करते समय इसे त्रुटिहीन माना जाता है।
डेटाबेस
कई सूचना प्रणालियों का उद्देश्य ज्ञान उत्पन्न करने के लिए डेटा को जानकारी में बदलना है जिसका उपयोग निर्णय लेने के लिए किया जा सकता है। ऐसा करने के लिए, सिस्टम को डेटा लेना या पढ़ना चाहिए, फिर डेटा को संदर्भ में रखना चाहिए, और एकत्रीकरण और विश्लेषण के लिए उपकरण प्रदान करना चाहिए। एक डेटाबेस को इस तरह के उद्देश्य के लिए डिज़ाइन किया गया है।
डेटाबेस संबंधित जानकारी का एक संगठित, सार्थक संग्रह है। यह एक संगठित संग्रह है, क्योंकि एक डेटाबेस में, सभी डेटा एक दूसरे से जुड़े होते हैं और अन्य डेटा के साथ जुड़े होते हैं। डेटाबेस में सभी जानकारी संबंधित होनी चाहिए; असंबंधित जानकारी को प्रबंधित करने के लिए अलग-अलग डेटाबेस बनाए जाने चाहिए। उदाहरण के लिए, एक डेटाबेस जिसमें कर्मचारियों के पेरोल के बारे में जानकारी है, कंपनी के शेयर की कीमतों के बारे में जानकारी भी नहीं रखनी चाहिए। डिजिटल डेटाबेस में एमएस एक्सेल द्वारा बनाई गई चीजें शामिल हैं, जैसे कि टेबल से लेकर लोगों द्वारा हर दिन उपयोग किए जाने वाले अधिक जटिल डेटाबेस, बैंक में अपने बैलेंस की जांच करने से लेकर मेडिकल रिकॉर्ड तक पहुंचने और ऑनलाइन शॉपिंग तक पहुंचने तक। डेटाबेस हमें अनावश्यक जानकारी को खत्म करने में मदद करते हैं। यह खोजों तक पहुंचने के लिए अधिक प्रभावी तरीके सुनिश्चित करता है। दिन में वापस, डेटाबेस हम एक फाइलिंग कैबिनेट बन सकते हैं। इस पाठ के लिए, हम केवल डिजिटल डेटाबेस पर विचार करेंगे।
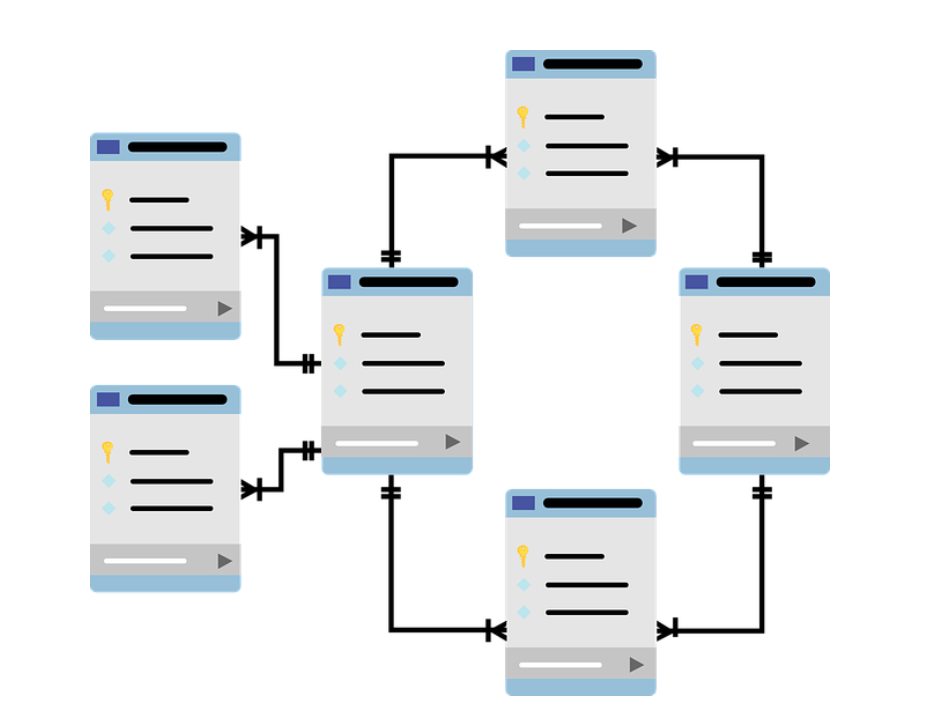
रिलेशनल डेटाबेस
डेटाबेस को कई अलग-अलग तरीकों से व्यवस्थित किया जा सकता है और इस प्रकार कई रूप ले सकते हैं। DBMS (डेटाबेस मैनेजमेंट सिस्टम) एक सॉफ्टवेयर है जो डेटा के संगठन और हेरफेर की सुविधा देता है। DBMS डेटाबेस और एंड-यूज़र के बीच एक इंटरफ़ेस के रूप में कार्य करता है। सॉफ़्टवेयर को डेटाबेस में डेटा को संग्रहीत करने, परिभाषित करने, पुनर्प्राप्त करने और प्रबंधित करने के लिए डिज़ाइन किया गया है। डेटाबेस के अन्य रूप आज रिलेशनल डेटाबेस हैं। रिलेशनल डेटाबेस के उदाहरण Oracle (RDBMS), MySQL, SQL और PostgreSQL हैं। एक रिलेशनल डेटाबेस वह है जिसमें पंक्तियों और स्तंभों के व्यवस्थित तरीके से डेटा संग्रहीत किया जाता है, जो संबंधित जानकारी की एक या अधिक तालिकाओं का निर्माण करेगा। प्रत्येक तालिका में फ़ील्ड का एक सेट होता है, जो तालिका में संग्रहीत डेटा की प्रकृति को परिभाषित करता है। एक रिकॉर्ड तालिका में फ़ील्ड के एक सेट का एक उदाहरण है। इसे देखने के लिए, एक्सेल स्प्रेडशीट, तालिका की पंक्तियों के रूप में रिकॉर्ड और तालिका कॉलम के रूप में फ़ील्ड के बारे में सोचें। नीचे दिए गए उदाहरण में, हमारे पास छात्र जानकारी की एक तालिका है, जिसमें प्रत्येक पंक्ति एक छात्र का प्रतिनिधित्व करती है और प्रत्येक कॉलम छात्र के बारे में एक जानकारी का प्रतिनिधित्व करता है। रिलेशनल डेटाबेस मॉडल अच्छी तरह से स्केल नहीं करता है। यहां स्केल शब्द एक बड़े और बड़े डेटाबेस को संदर्भित करता है जो नेटवर्क के माध्यम से जुड़े कंप्यूटरों की एक बड़ी संख्या पर वितरित किया जा रहा है। कुछ कंपनियां रिलेशनल मॉडल से दूसरे, अधिक लचीले मॉडल से दूर जाकर बड़े पैमाने पर डेटाबेस समाधान प्रदान करना चाह रही हैं। उदाहरण के लिए, Google अब ऐप इंजन डेटास्टोर प्रदान करता है, जो NoSQL पर आधारित है। डेवलपर दुनिया में कहीं से भी डेटा एक्सेस करने वाले एप्लिकेशन विकसित करने के लिए ऐप इंजन डेटास्टोर का उपयोग कर सकते हैं। Amazon.com एंटरप्राइज़ उपयोग के लिए कई डेटाबेस सेवाएं प्रदान करता है, जिसमें Amazon RDS, एक रिलेशनल डेटाबेस सेवा और Amazon DynamoDB, एक NoSQL एंटरप्राइज़ समाधान शामिल हैं।
रिलेशनल डेटाबेस उदाहरण
|
फ़ील्ड (कॉलम) |
||||
|
रिकॉर्ड्स (पंक्तियाँ) |
पहला नाम |
अंतिम नाम |
मेजर |
जन्म दिन |
|
ऐन मैरी |
मज़बूत |
प्री-लॉ |
2/27/1997 |
|
|
इवान |
दाएँ |
बिज़नेस |
12/4/1996 |
|
|
मिशेल |
स्मिथ |
मैथ |
6/27/1995 |
|