
6.9: Kufaa Mifano ya Kielelezo kwa Data
- Page ID
- 180901

- Kujenga mfano kielelezo kutoka data.
- Jenga mfano wa logarithmic kutoka data.
- Kujenga mfano wa vifaa kutoka data.
Katika sehemu ya awali ya sura hii, sisi walikuwa ama kupewa kazi wazi kwa grafu au kutathmini, au tulipewa seti ya pointi kwamba walikuwa uhakika wa uongo juu ya Curve. Kisha sisi kutumika algebra kupata equation kwamba inafaa pointi hasa. Katika sehemu hii, sisi kutumia mbinu modeling aitwaye regression uchambuzi kupata Curve kwamba mifano data zilizokusanywa kutoka uchunguzi halisi ya dunia. Kwa uchambuzi wa kurudi nyuma, hatutarajii pointi zote kulala kikamilifu kwenye safu. Wazo ni kupata mfano unaofaa zaidi data. Kisha tunatumia mfano wa kufanya utabiri kuhusu matukio ya baadaye.
Usichanganyike na mfano wa neno. Katika hisabati, sisi mara nyingi kutumia maneno kazi, equation, na mfano interchangeably, hata kama kila mmoja wao wenyewe rasmi ufafanuzi. Mfano wa neno hutumiwa kuonyesha kwamba equation au kazi inakaribia hali halisi ya ulimwengu.
Tutazingatia aina tatu za mifano ya kurudi nyuma katika sehemu hii: kielelezo, logarithmic, na vifaa. Baada ya kufanya kazi na kila kazi hizi hutupa faida. Kujua ufafanuzi wao rasmi, tabia ya grafu zao, na baadhi ya maombi yao halisi ya dunia inatupa fursa ya kuimarisha uelewa wetu. Kama kila mfano wa kurudi nyuma unawasilishwa, vipengele muhimu na ufafanuzi wa kazi yake inayohusishwa ni pamoja na kwa ajili ya ukaguzi. Kuchukua muda wa kufikiri upya kila moja ya kazi hizi, kutafakari juu ya kazi tumefanya hadi sasa, na kisha kuchunguza njia regression hutumiwa kutengeneza matukio halisi ya ulimwengu.
Kujenga Mfano wa Kielelezo kutoka Data
Kama tulivyojifunza, kuna hali nyingi ambazo zinaweza kuonyeshwa na kazi za kielelezo, kama vile ukuaji wa uwekezaji, kuoza kwa mionzi, mabadiliko ya shinikizo la anga, na joto la kitu kilichopoza. Je, matukio haya yanafanana nini? Kwa jambo moja, mifano yote huongeza au kupungua kama wakati unaendelea mbele. Lakini hiyo siyo hadithi nzima. Ni njia ya kuongeza data au kupungua ambayo inatusaidia kuamua kama ni bora inatokana na equation kielelezo. Kujua tabia ya kazi za kielelezo kwa ujumla inatuwezesha kutambua wakati wa kutumia regression ya kielelezo, basi hebu tupate ukuaji wa kielelezo na kuoza.
Kumbuka kwamba kazi za kielelezo zina fomu\(y=ab^x\) au\(y=A_0e^{kx}\). Wakati wa kufanya uchambuzi wa kurudi nyuma, tunatumia fomu inayotumiwa zaidi kwenye huduma za kuchora,\(y=ab^x\). Chukua muda wa kutafakari juu ya sifa ambazo tayari tumejifunza kuhusu kazi ya kielelezo\(y=ab^x\) (kudhani\(a>0\)):
- \(b\)lazima iwe kubwa kuliko sifuri na si sawa na moja.
- Thamani ya awali ya mfano ni\(y=a\).
- Kama\(b>1\), kazi mifano ya ukuaji kielelezo. Kama\(x\) ongezeko, matokeo ya mfano huongezeka polepole kwa mara ya kwanza, lakini kisha kuongezeka kwa kasi zaidi na zaidi, bila kufungwa.
- Kama\(0<b<1\), kazi mifano kielelezo kuoza. Kama\(x\) ongezeko, matokeo ya mfano hupungua kwa kasi kwa mara ya kwanza na kisha ngazi mbali ili kuwa asymptotic kwa x -axis. Kwa maneno mengine, matokeo hayakuwa sawa au chini ya sifuri.
Kama sehemu ya matokeo, calculator yako kuonyesha idadi inayojulikana kama uwiano mgawo, kinachoitwa na variable\(r\), au\(r^2\). (Unaweza kuwa na mabadiliko ya mipangilio calculator kwa ajili ya haya kuonyeshwa.) Maadili ni dalili ya “wema wa fit” ya equation regression kwa data. Sisi zaidi ya kawaida kutumia thamani ya\(r^2\) badala ya\(r\), lakini karibu ama thamani ni\(1\), bora equation regression approximates data.
Ukandamizaji wa kielelezo hutumika kuiga hali ambazo ukuaji huanza polepole halafu huharakisha haraka bila kufungwa, au pale ambapo kuoza huanza haraka na kisha kupungua chini ili kupata karibu na karibu na sifuri. Tunatumia amri “ExPreg” kwenye matumizi ya graphing ili kuunganisha kazi ya kielelezo kwenye seti ya pointi za data. Hii anarudi equation ya fomu,
\[y=ab^x\]
Kumbuka kwamba:
- \(b\)lazima yasiyo ya hasi.
- wakati\(b>1\), tuna mfano wa ukuaji wa kielelezo.
- wakati\(0<b<1\), tuna kielelezo kuoza mfano.
- Tumia STAT kisha EDIT menu kuingia data iliyotolewa.
- Futa data yoyote iliyopo kutoka kwenye orodha.
- Andika orodha ya maadili ya pembejeo kwenye safu ya L1.
- Andika orodha ya maadili ya pato kwenye safu ya L2.
- Grafu na kuchunguza kutawanya njama ya data kwa kutumia kipengele STATPLOT.
- Tumia ZOOM [9] ili kurekebisha shaba ili ufanane na data.
- Thibitisha data kufuata mfano wa kielelezo.
- Find equation kwamba mifano ya data.
- Kuchagua “ExPreg” kutoka STAT kisha CALC menu.
- Matumizi maadili akarudi kwa na b kurekodi mfano,\(y=ab^x\).
- Grafu mfano katika dirisha moja kama scatterplot kuthibitisha ni fit nzuri kwa data.
Mfano\(\PageIndex{1}\): Using Exponential Regression to Fit a Model to Data
Mwaka 2007, utafiti wa chuo kikuu ulichapishwa kuchunguza hatari ya ajali ya kuendesha gari kuharibika kwa pombe. Takwimu kutoka kwa\(2,871\) ajali zilitumika kupima ushirikiano wa kiwango cha pombe cha damu ya mtu (BAC) na hatari ya kuwa katika ajali. Jedwali\(\PageIndex{1}\) linaonyesha matokeo kutoka kwa utafiti. Hatari ya jamaa ni kipimo cha mara ngapi mtu anaweza kuanguka. Kwa hiyo, kwa mfano, mtu mwenye BAC ya\(3.54\) mara\(0.09\) ni uwezekano wa kuanguka kama mtu ambaye hajawahi kunywa pombe.
| BAC | 0 | 0.01 | 0.03 | 0.05 | 0.07 | 0.09 |
|---|---|---|---|---|---|---|
| Jamaa Hatari ya Crashing | 1 | 1.03 | 1.06 | 1.38 | 2.09 | 3.54 |
| BAC | 0.11 | 0.13 | 0.15 | 0.17 | 0.19 | 0.21 |
| Jamaa Hatari ya Crashing | 6.41 | 12.6 | 22.1 | 39.05 | 65.32 | 99.78 |
- Hebu\(x\) kuwakilisha ngazi BAC, na basi\(y\) kuwakilisha sambamba jamaa hatari. Tumia regression kielelezo ili kufaa mfano wa data hizi.
- Baada ya\(6\) vinywaji, mtu mwenye uzito wa\(160\) paundi atakuwa na BAC ya karibu\(0.16\). Ni mara ngapi zaidi mtu mwenye uzito huu ajali ikiwa huendesha gari baada ya kuwa na\(6\) pakiti ya bia? Pande zote hadi karibu na mia moja.
Suluhisho
- Kutumia STAT kisha EDIT menu kwenye matumizi ya graphing, weka maadili ya BAC katika L1 na maadili ya hatari ya jamaa katika L2. Kisha kutumia kipengele STATPLOT kuthibitisha kwamba scatterplot ifuatavyo mfano kielelezo inavyoonekana katika Kielelezo\(\PageIndex{1}\):
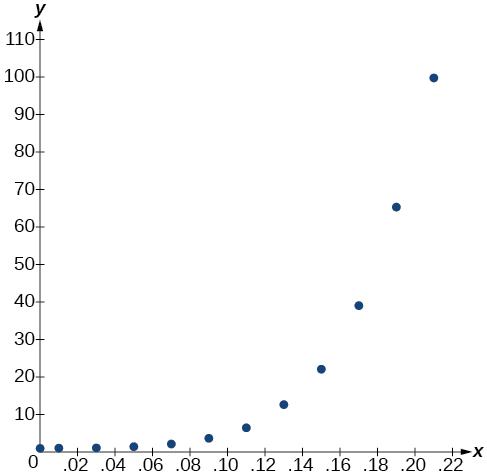
Kielelezo\(\PageIndex{1}\)
Tumia amri ya “ExPreg” kutoka kwenye orodha ya STAT kisha CALC ili kupata mfano wa kielelezo,
\(y=0.58304829{(2.20720213E10)}^x\)
Kubadilisha kutoka kwa notation ya kisayansi, tuna:
\(y=0.58304829{(22,072,021,300)}^x\)
Angalia kwamba\(r^2≈0.97\) ambayo inaonyesha mfano ni fit nzuri kwa data. Ili kuona hili, graph mfano katika dirisha moja kama scatterplot kuthibitisha ni fit nzuri kama inavyoonekana katika Kielelezo\(\PageIndex{2}\):
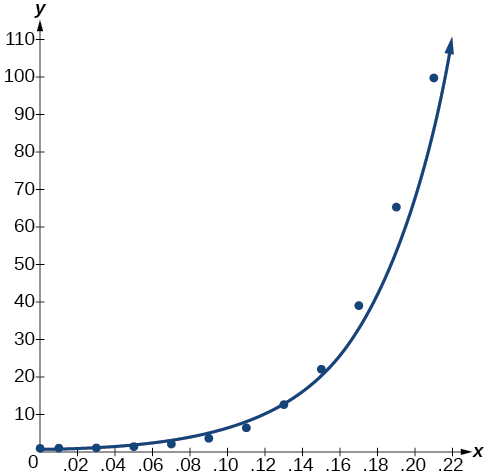
Kielelezo\(\PageIndex{2}\)
- Kutumia mfano wa kukadiria hatari ya kuhusishwa na BAC ya\(0.16\). \(0.16\)\(x\)Kubadilisha kwa mfano na kutatua\(y\).
\[\begin{align*} y&= 0.58304829{(22,072,021,300)}^x \qquad \text{Use the regression model found in part } (a)\\ &= 0.58304829{(22,072,021,300)}^{0.16} \qquad \text{Substitute 0.16 for x}\\ &\approx 26.35 \qquad \text{Round to the nearest hundredth} \end{align*}\]
Kama mtu\(160\) -pauni anatoa baada ya kuwa na\(6\) vinywaji, yeye ni kuhusu\(26.35\) mara zaidi uwezekano wa ajali kuliko kama kuendesha gari wakati kiasi.
Jedwali\(\PageIndex{2}\) linaonyesha hivi karibuni kuhitimu kadi ya mikopo mizani kila mwezi baada ya kuhitimu.
| Mwezi | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Madeni ($) | 620.00 | 761.88 | 899.80 | 1039.93 | 1270.63 | 1589.04 | 1851.31 | 2154.92 |
- Tumia regression kielelezo ili kufaa mfano wa data hizi.
- Ikiwa matumizi yanaendelea kwa kiwango hiki, madeni ya kadi ya mkopo ya mhitimu itakuwa mwaka mmoja baada ya kuhitimu?
- Jibu
-
kielelezo regression mfano kwamba inafaa data hizi ni\(y=522.88585984{(1.19645256)}^x\).
- Jibu b
-
Ikiwa matumizi yanaendelea kwa kiwango hiki, madeni ya kadi ya mkopo ya mhitimu itakuwa\($4,499.38\) baada ya mwaka mmoja.
Hapana. Kumbuka kwamba mifano ni sumu na data halisi ya dunia zilizokusanywa kwa regression. Kwa kawaida ni busara kufanya makadirio ndani ya muda wa uchunguzi wa awali (tafsiri). Hata hivyo, wakati mfano unatumiwa kufanya utabiri, ni muhimu kutumia ujuzi wa hoja ili kuamua kama mfano una maana kwa pembejeo mbali zaidi ya muda wa uchunguzi wa awali (extrapolation).
Kujenga Mfano wa Logarithmic kutoka Data
Kama ilivyo na kazi za kielelezo, kuna maombi mengi ya ulimwengu halisi ya kazi za logarithmic: ukubwa wa sauti, viwango vya pH vya ufumbuzi, mavuno ya athari za kemikali, uzalishaji wa bidhaa, na ukuaji wa watoto wachanga. Kama ilivyo kwa mifano ya kielelezo, data inayotokana na kazi za logarithmic ni ama kuongezeka daima au daima kupungua kama wakati unaendelea mbele. Tena, ndio njia wanayoongeza au kupungua ambayo inatusaidia kuamua kama mfano wa logarithmic ni bora.
Kumbuka kwamba kazi za logarithmic zinaongezeka au kupungua kwa kasi kwa mara ya kwanza, lakini kisha hupungua kwa kasi kama wakati unaendelea. Kwa kutafakari juu ya sifa ambazo tayari tumejifunza kuhusu kazi hii, tunaweza kuchambua vizuri hali halisi za ulimwengu zinazoonyesha aina hii ya ukuaji au kuoza. Wakati wa kufanya uchambuzi wa regression wa logarithmic, tunatumia fomu ya kazi ya logarithmic ambayo hutumiwa kwa kawaida kwenye huduma za kuchora,\(y=a+b\ln(x)\). Kwa kazi hii
- Maadili yote ya pembejeo\(x\),, lazima iwe kubwa kuliko sifuri.
- Hatua\((1,a)\) ni kwenye grafu ya mfano.
- Ikiwa\(b>0\), mfano unaongezeka. Ukuaji huongezeka kwa kasi kwa mara ya kwanza na kisha hupungua kwa muda.
- Ikiwa\(b<0\), mfano huo unapungua. Kuoza hutokea haraka kwa mara ya kwanza na kisha hupungua kwa muda.
Ukandamizaji wa logarithmic hutumiwa kutengeneza hali ambapo ukuaji au kuoza huharakisha haraka kwa mara ya kwanza na kisha hupungua kwa muda. Tunatumia amri “LnReg” kwenye matumizi ya graphing ili kuunganisha kazi ya logarithmic kwa seti ya pointi za data. Hii anarudi equation ya fomu,
\[y=a+b\ln(x)\]
Kumbuka kwamba
- maadili yote pembejeo,\(x\), lazima zisizo hasi.
- wakati\(b>0\), mfano unaongezeka.
- wakati\(b<0\), mfano huo unapungua.
- Tumia STAT kisha EDIT menu kuingia data iliyotolewa.
- Futa data yoyote iliyopo kutoka kwenye orodha.
- Andika orodha ya maadili ya pembejeo kwenye safu ya L1.
- Andika orodha ya maadili ya pato kwenye safu ya L2.
- Grafu na kuchunguza kutawanya njama ya data kwa kutumia kipengele STATPLOT.
- Tumia ZOOM [9] ili kurekebisha shaba ili ufanane na data.
- Thibitisha data kufuata muundo wa logarithmic.
- Find equation kwamba mifano ya data.
- Chagua “LnReg” kutoka STAT kisha CALC menu.
- Matumizi maadili akarudi kwa na b kurekodi mfano,\(y=a+b\ln(x)\).
- Grafu mfano katika dirisha moja kama scatterplot kuthibitisha ni fit nzuri kwa data.
Kutokana na maendeleo katika dawa na viwango vya juu vya maisha, matarajio ya maisha yameongezeka katika nchi nyingi zilizoendelea tangu mwanzo wa karne ya 20. Jedwali\(\PageIndex{3}\) linaonyesha wastani wa matarajio ya maisha, katika miaka, ya Wamarekani kutoka 1900—2010.
| Mwaka | 1900 | 1910 | 1920 | 1930 | 1940 | 1950 |
|---|---|---|---|---|---|---|
| Matarajio ya Maisha (Miaka) | 47.3 | 50.0 | 54.1 | 59.7 | 62.9 | 68.2 |
| Mwaka | 1960 | 1970 | 1980 | 1990 | 2000 | 2010 |
| Matarajio ya Maisha (Miaka) | 69.7 | 70.8 | 73.7 | 75.4 | 76.8 | 78.7 |
- Hebu\(x\) kuwakilisha muda katika miongo kadhaa kuanzia na\(x=1\) kwa mwaka 1900,\(x=2\) kwa mwaka 1910, na kadhalika. Hebu\(y\) kuwakilisha matarajio ya maisha yanayofanana. Tumia regression ya logarithmic ili kufanana na mfano wa data hizi.
- Tumia mfano kutabiri wastani wa matarajio ya maisha ya Marekani kwa mwaka 2030.
Suluhisho
- Kutumia STAT kisha orodha ya EDIT kwenye matumizi ya graphing, weka orodha ya miaka kwa kutumia maadili\(1–12\) katika L1 na matarajio ya kuishi yanayofanana katika L2. Kisha kutumia kipengele STATPLOT kuthibitisha kwamba scatterplot ifuatavyo muundo logarithmic kama inavyoonekana katika Kielelezo\(\PageIndex{3}\):
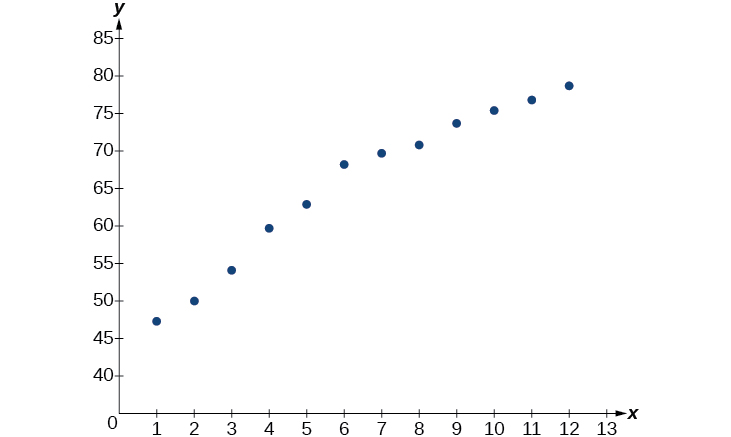
Kielelezo\(\PageIndex{3}\)
Tumia amri ya “LnReg” kutoka kwa STAT kisha orodha ya CALC ili kupata mfano wa logarithmic,
\(y=42.52722583+13.85752327\ln(x)\)
Kisha, graph mfano katika dirisha moja kama scatterplot kuthibitisha ni fit nzuri kama inavyoonekana katika Kielelezo\(\PageIndex{4}\):
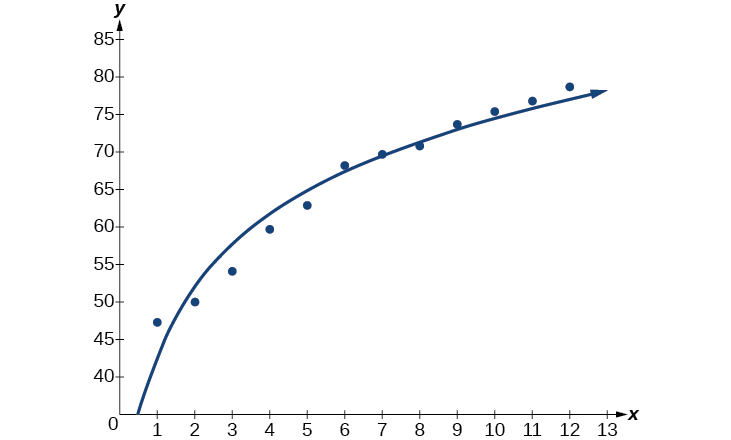
Kielelezo\(\PageIndex{4}\)
- Kutabiri matarajio ya maisha ya Amerika mwaka\(2030\), badala\(x=14\) ya mfano na kutatua kwa\(y\):
\[\begin{align*} y&= 42.52722583+13.85752327\ln(x) \qquad \text{Use the regression model found in part } (a)\\ &= 42.52722583+13.85752327\ln(14) \qquad \text{Substitute 14 for x}\\ &\approx 79.1 \qquad \text{Round to the nearest tenth} \end{align*}\]
Ikiwa matarajio ya maisha yanaendelea kuongezeka kwa kasi hii, wastani wa kuishi wa Amerika utakuwa\(79.1\) kwa mwaka\(2030\).
Mauzo ya mchezo wa video iliyotolewa mwaka wa 2000 yaliondoka kwa mara ya kwanza, lakini kisha ikapungua kasi kama muda uliendelea. Jedwali\(\PageIndex{4}\) linaonyesha idadi ya michezo kuuzwa, katika maelfu, kutoka miaka 2000—2010.
| Mwaka | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 |
|---|---|---|---|---|---|---|
| Idadi kuuzwa (maelfu) | 142 | 149 | 154 | 155 | 159 | 161 |
| Mwaka | 2006 | 2007 | 2008 | 2009 | 2010 | - |
| Idadi kuuzwa (maelfu) | 163 | 164 | 164 | 166 | 167 | - |
Hebu\(x\) kuwakilisha muda katika miaka kuanzia na\(x=1\) kwa mwaka 2000. Hebu\(y\) kuwakilisha idadi ya michezo kuuzwa kwa maelfu.
- Tumia regression ya logarithmic ili kufanana na mfano wa data hizi.
- Ikiwa michezo itaendelea kuuza kwa kiwango hiki, ni michezo ngapi itauza mwaka 2015? Pande zote kwa elfu ya karibu.
- Jibu
-
Mfano wa regression wa logarithmic unaofaa data hizi ni\(y=141.91242949+10.45366573\ln(x)\)
- Jibu b
-
Kama mauzo itaendelea kwa kiwango hiki, kuhusu\(171,000\) michezo itakuwa kuuzwa katika mwaka\(2015\).
Kujenga Mfano wa Vifaa kutoka Data
Kama ukuaji wa kielelezo na logarithmic, ukuaji wa vifaa huongezeka kwa muda. Moja ya tofauti maarufu zaidi na mifano ya ukuaji wa vifaa ni kwamba, kwa wakati fulani, ukuaji hupungua kwa kasi na kazi inakaribia kufungwa juu, au thamani ya kupunguza. Kwa sababu hii, vifaa regression ni bora kwa ajili ya modeling matukio ambapo kuna mipaka katika upanuzi, kama vile upatikanaji wa nafasi ya kuishi au virutubisho.
Ni muhimu kusema kwamba kazi za vifaa kwa kweli zinaonyesha ukuaji wa rasilimali mdogo. Kuna mifano mingi ya aina hii ya ukuaji katika hali halisi ya ulimwengu, ikiwa ni pamoja na ukuaji wa idadi ya watu na kuenea kwa magonjwa, uvumi, na hata stains katika kitambaa. Wakati wa kufanya uchambuzi wa regression wa vifaa, tunatumia fomu inayotumiwa kwa kawaida kwenye huduma za kuchora:
\(y=\dfrac{c}{1+ae^{−bx}}\)
Kumbuka kwamba:
- \(\dfrac{c}{1+a}\)ni thamani ya awali ya mfano.
- wakati\(b>0\), mfano huongezeka kwa kasi kwa mara ya kwanza mpaka kufikia hatua yake ya kiwango cha juu cha ukuaji,\((\dfrac{\ln(a)}{b}, \dfrac{c}{2})\). Katika hatua hiyo, ukuaji hupungua kwa kasi na kazi inakuwa isiyo ya kawaida kwa kufungwa kwa juu\(y=c\).
- \(c\)ni thamani ya kupunguza, wakati mwingine huitwa uwezo wa kubeba, ya mfano.
Ukandamizaji wa vifaa hutumiwa kutengeneza hali ambapo ukuaji huharakisha haraka kwa mara ya kwanza na kisha hupungua kwa kasi hadi kikomo cha juu. Tunatumia amri ya “Vifaa” kwenye matumizi ya graphing ili kufaa kazi ya vifaa kwa seti ya pointi za data. Hii anarudi equation ya fomu
\[y=\dfrac{c}{1+ae^{−bx}}\]
Kumbuka kwamba
- Thamani ya awali ya mfano ni\(\dfrac{c}{1+a}\).
- Maadili ya pato kwa mfano hukua karibu na karibu na wakati\(y=c\) unavyoongezeka.
- Tumia STAT kisha EDIT menu kuingia data iliyotolewa.
- Futa data yoyote iliyopo kutoka kwenye orodha.
- Andika orodha ya maadili ya pembejeo kwenye safu ya L1.
- Andika orodha ya maadili ya pato kwenye safu ya L2.
- Grafu na kuchunguza kutawanya njama ya data kwa kutumia kipengele STATPLOT.
- Tumia ZOOM [9] ili kurekebisha shaba ili ufanane na data.
- Thibitisha data kufuata muundo wa vifaa.
- Find equation kwamba mifano ya data.
- Chagua “Vifaa” kutoka STAT kisha CALC menu.
- Tumia maadili yaliyorejeshwa\(a\)\(b\),, na\(c\) kurekodi mfano,\(y=\dfrac{c}{1+ae^{−bx}}\).
- Grafu mfano katika dirisha moja kama scatterplot kuthibitisha ni fit nzuri kwa data.
Huduma ya simu za mkononi imeongezeka kwa kasi katika Amerika tangu katikati ya miaka ya 1990. Leo, karibu wakazi wote wana huduma za mkononi. Jedwali\(\PageIndex{5}\) linaonyesha asilimia ya Wamarekani na huduma za mkononi kati ya miaka 1995 na 2012.
| Mwaka | Wamarekani na Huduma za mkononi (%) | Mwaka | Wamarekani na Huduma za mkononi (%) |
|---|---|---|---|
| 1995 | 12.69 | 2004 | 62.852 |
| 1996 | 16.35 | 2005 | 68.63 |
| 1997 | 20.29 | 2006 | 76.64 |
| 1998 | 25.08 | 2007 | 82.47 |
| 1999 | 30.81 | 2008 | 85.68 |
| 2000 | 38.75 | 2009 | 89.14 |
| 2001 | 45.00 | 2010 | 91.86 |
| 2002 | 49.16 | 2011 | 95.28 |
| 2003 | 55.15 | 2012 | 98.17 |
- Hebu\(x\) kuwakilisha muda katika miaka kuanzia na\(x=0\) kwa mwaka 1995. Hebu\(y\) kuwakilisha asilimia sawa ya wakazi wenye huduma za mkononi. Tumia regression ya vifaa ili kufaa mfano wa data hizi.
- Tumia mfano wa kuhesabu asilimia ya Wamarekani wenye huduma ya kiini katika mwaka 2013. Pande zote kwa karibu kumi ya asilimia.
- Jadili thamani akarudi kwa kikomo juu,\(c\). Hii inakuambia nini kuhusu mfano? Thamani ya kikwazo ingekuwa nini ikiwa mfano ulikuwa halisi?
Suluhisho
- Kutumia STAT kisha EDIT menu kwenye matumizi ya graphing, orodha ya miaka kwa kutumia maadili\(0–15\) katika L1 na asilimia sambamba katika L2. Kisha kutumia kipengele STATPLOT kuthibitisha kwamba scatterplot ifuatavyo muundo vifaa kama inavyoonekana katika Kielelezo\(\PageIndex{5}\):
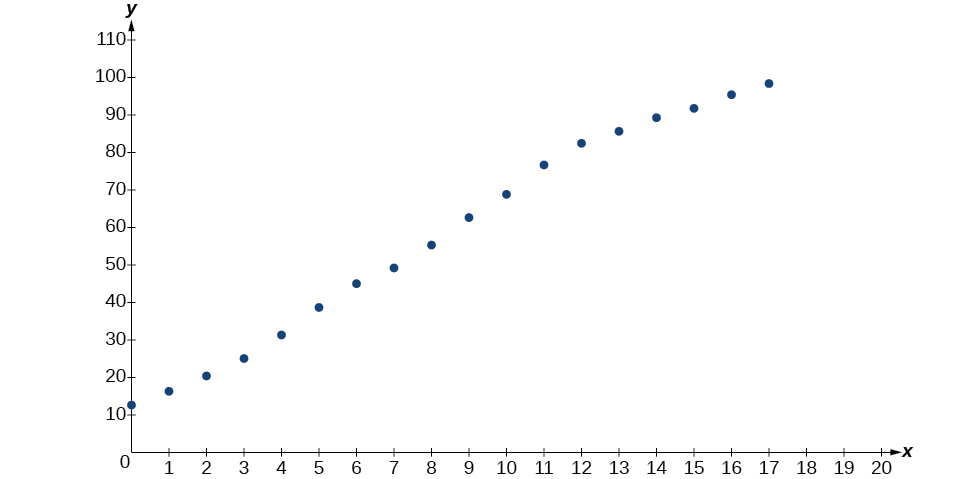
Kielelezo\(\PageIndex{5}\)
Tumia amri ya “Vifaa” kutoka kwenye orodha ya STAT kisha CALC ili kupata mfano wa vifaa,
\[y=105.73795261+6.88328979e^{−0.2595440013x}\]
Kisha, graph mfano katika dirisha moja kama inavyoonekana katika Kielelezo\(\PageIndex{6}\) scatterplot kuthibitisha ni fit nzuri:
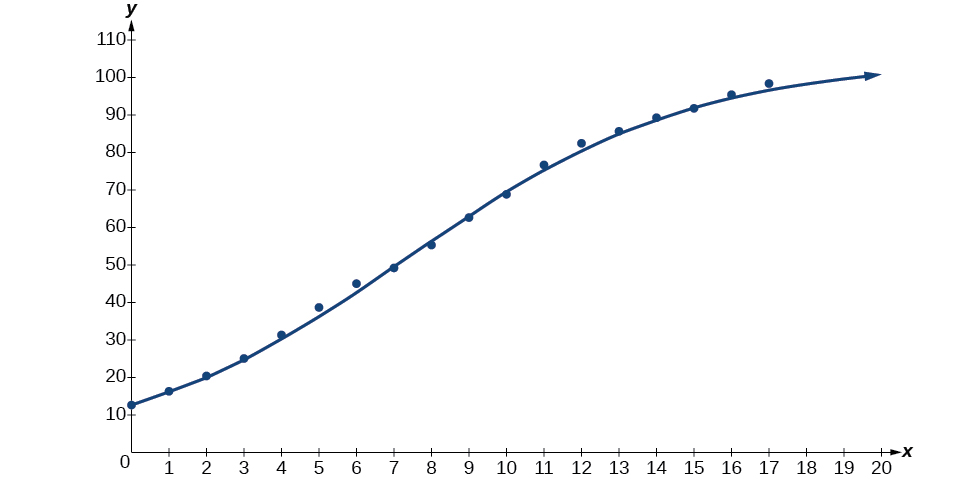
Kielelezo\(\PageIndex{6}\)
- Kwa takriban asilimia ya Wamarekani na huduma za mkononi katika mwaka 2013, badala\(x=18\) ya katika mfano na kutatua kwa\(y\):
\[\begin{align*} y&= \dfrac{105.7379526}{1+6.88328979e^{-0.2595440013x}} \qquad \text{Use the regression model found in part } (a)\\ &= \dfrac{105.7379526}{1+6.88328979e^{-0.2595440013(18)}} \qquad \text{Substitute 18 for x}\\ &\approx 99.3 \qquad \text{Round to the nearest tenth} \end{align*}\]
Kwa mujibu wa mfano, kuhusu 98.8% ya Wamarekani walikuwa na huduma za mkononi mwaka 2013.
- Mfano hutoa thamani ya upeo wa karibu\(105\). Hii ina maana kwamba asilimia kubwa ya Wamarekani wenye huduma za mkononi itakuwa\(105%\), ambayo haiwezekani. (Jinsi gani zaidi\(100%\) ya idadi ya watu na huduma za mkononi?) Kama mfano walikuwa halisi, thamani kikwazo itakuwa\(c=100\) na matokeo ya mfano wa kupata karibu sana na, lakini kamwe kweli kufikia\(100%\). Baada ya yote, daima kutakuwa na mtu huko nje bila huduma za mkononi!
Jedwali\(\PageIndex{6}\) linaonyesha idadi ya watu, kwa maelfu, ya mihuri bandari katika Bahari ya Wadden zaidi ya miaka 1997 kwa 2012.
| Mwaka | Seal Idadi ya Watu (Maelfu) | Mwaka | Seal Idadi ya Watu (Maelfu) |
|---|---|---|---|
| 1997 | 3.493 | 2005 | 19.590 |
| 1998 | 5.282 | 2006 | 21.955 |
| 1999 | 6.357 | 2007 | 22.862 |
| 2000 | 9.201 | 2008 | 23.869 |
| 2001 | 11.224 | 2009 | 24.243 |
| 2002 | 12.964 | 2010 | 24.344 |
| 2003 | 16.226 | 2011 | 24.919 |
| 2004 | 18.137 | 2012 | 25.108 |
Hebu\(x\) kuwakilisha muda katika miaka kuanzia na\(x=0\) kwa mwaka 1997. Hebu\(y\) kuwakilisha idadi ya mihuri kwa maelfu.
- Tumia regression ya vifaa ili kufaa mfano wa data hizi.
- Tumia mfano kutabiri idadi ya muhuri kwa mwaka 2020.
- Kwa nambari nzima ya karibu, ni thamani gani ya upeo wa mfano huu?
- Jibu
-
vifaa regression mfano kwamba inafaa data hizi ni\(y=\dfrac{25.65665979}{1+6.113686306e^{−0.3852149008x}}\).
- Jibu b
-
Ikiwa idadi ya watu inaendelea kukua kwa kiwango hiki, kutakuwa na\(25,634\) mihuri katika 2020.
- Jibu c
-
Kwa nambari nzima ya karibu, uwezo wa kubeba ni\(25,657\).
Fikia rasilimali hii ya mtandaoni kwa maelekezo ya ziada na mazoezi na mifano ya kazi ya kielelezo.
Ziara tovuti hii kwa maswali ya ziada mazoezi kutoka Learningpod.
Dhana muhimu
- Ukandamizaji wa kielelezo hutumika kuiga hali ambapo ukuaji huanza polepole halafu huharakisha haraka bila kufungwa, au pale ambapo kuoza huanza haraka na kisha kupungua chini ili kupata karibu na karibu na sifuri.
- Tunatumia amri “ExPreg” kwenye matumizi ya graphing ili kuunganisha kazi ya fomu\(y=ab^x\) kwa seti ya pointi za data. Angalia Mfano\(\PageIndex{1}\).
- Ukandamizaji wa logarithmic hutumiwa kutengeneza hali ambapo ukuaji au kuoza huharakisha haraka kwa mara ya kwanza na kisha hupungua kwa muda.
- Tunatumia amri “LnReg” kwenye matumizi ya graphing ili kuunganisha kazi ya fomu\(y=a+b\ln(x)\) kwa seti ya pointi za data. Angalia Mfano\(\PageIndex{2}\).
- Ukandamizaji wa vifaa hutumiwa kutengeneza hali ambapo ukuaji huharakisha haraka mwanzoni na kisha kupungua kwa kasi kadiri kazi inakaribia kikomo cha juu.
- Tunatumia amri ya “Vifaa” kwenye matumizi ya graphing ili kuunganisha kazi ya fomu\(y=\dfrac{c}{1+ae^{−bx}}\) kwa seti ya pointi za data. Angalia Mfano\(\PageIndex{3}\).