
4.4: Criando um banco de dados
- Page ID
- 171133
Criando um banco de dados
Suponha que uma universidade queira criar um banco de dados para rastrear a participação em clubes estudantis. Depois de entrevistar várias pessoas, a equipe de design descobre que implementar o sistema é fornecer uma visão melhor de como a universidade financia os clubes. Isso será feito monitorando quantos sócios cada clube tem e quão ativos os clubes são. A equipe decide que o sistema deve acompanhar os clubes, seus sócios e seus eventos. Usando essas informações, a equipe de design determina que as seguintes tabelas precisam ser criadas:
- Clubes: isso rastreará o nome do clube, o presidente do clube e uma breve descrição do clube.
- Estudantes: nome do estudante, e-mail e ano de nascimento.
- Associações: esta tabela correlacionará estudantes com clubes, permitindo que qualquer aluno participe de vários clubes.
- Eventos: esta tabela registrará quando os clubes se reúnem e quantos estudantes compareceram.
Agora que a equipe de design determinou quais tabelas criar, ela precisa definir as informações específicas que cada tabela conterá. Isso requer a identificação dos campos que estarão em cada tabela. Por exemplo, Nome do clube seria um dos campos na tabela Clubes. Nome e sobrenome seriam campos na tabela Estudantes. Finalmente, como esse será um banco de dados relacional, cada tabela deve ter um campo em comum com pelo menos uma outra tabela (em outras palavras: elas devem ter uma relação entre si).
Para criar adequadamente esse relacionamento, uma chave primária deve ser selecionada para cada tabela. Essa chave é um identificador exclusivo para cada registro na tabela. Por exemplo, na tabela Alunos, talvez seja possível usar os primeiros nomes dos alunos para identificá-los de forma exclusiva. No entanto, é mais do que provável que alguns alunos compartilhem o sobrenome (como Mike, Stefanie ou Chris), portanto, um campo diferente deve ser selecionado. O endereço de e-mail de um aluno pode ser uma boa opção para uma chave primária, pois os endereços de e-mail são exclusivos. No entanto, uma chave primária não pode mudar, então isso significaria que, se os alunos mudassem seus endereços de e-mail, teríamos que removê-los do banco de dados e depois inseri-los novamente, o que não é uma proposta atraente. Nossa solução é criar um valor para cada aluno — uma ID de usuário — que funcionará como uma chave primária. Também faremos isso para cada um dos clubes estudantis. Essa solução é bastante comum e é a razão pela qual você tem tantos IDs de usuário!
Você pode ver o design final do banco de dados na figura abaixo:
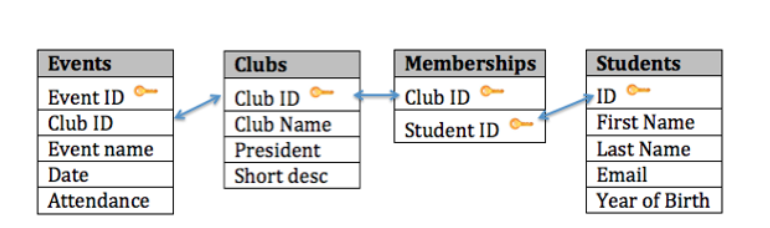
Com esse design, não só temos uma maneira de organizar todas as informações necessárias para atender aos requisitos, mas também relacionamos com sucesso todas as tabelas. Veja como as tabelas do banco de dados podem parecer com alguns dados de amostra. Observe que a tabela de Associações tem o único propósito de nos permitir relacionar vários estudantes a vários clubes.
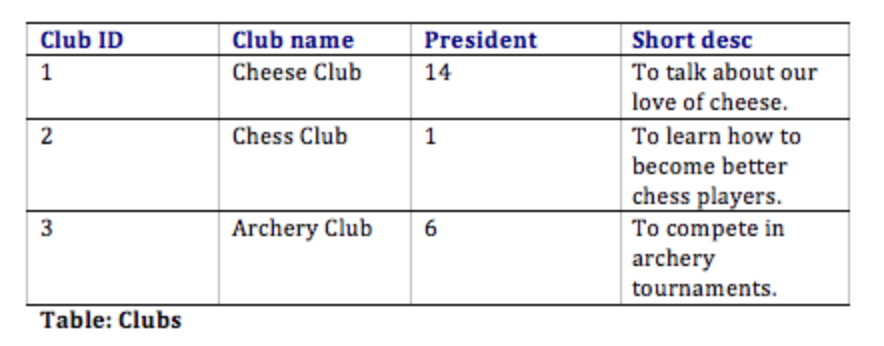
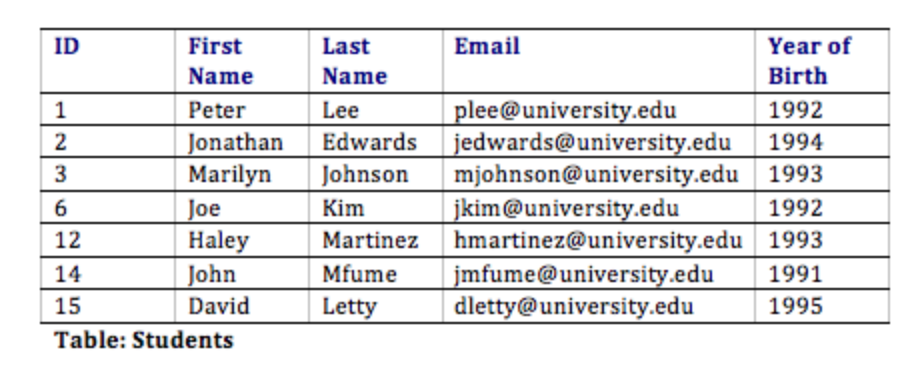
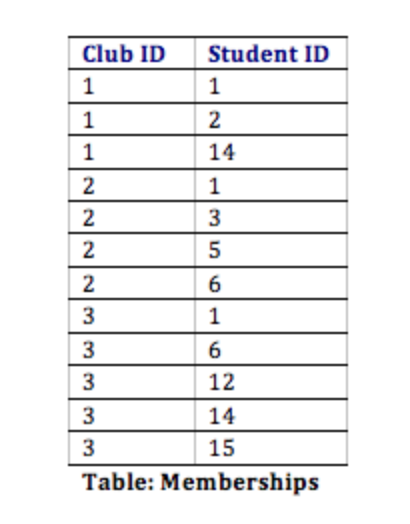
Normalização
Ao criar um banco de dados, um conceito importante a ser entendido é a normalização. Em termos simples, normalizar um banco de dados significa projetá-lo de uma forma que:
- Reduz a redundância de dados entre tabelas, mapeamento mais fácil
- Elimina dados inconsistentes.
- As informações são armazenadas em um único local.
- Oferece à mesa o máximo de flexibilidade possível.
No design do banco de dados do Student Clubs, a equipe de design trabalhou para atingir esses objetivos. Por exemplo, para rastrear associações, uma solução simples pode ter sido criar um campo Membros na tabela Clubes e, em seguida, listar todos os nomes dos associados. No entanto, esse design significaria que, se um estudante ingressasse em dois clubes, suas informações precisariam ser inseridas pela segunda vez. Em vez disso, os designers resolveram esse problema usando duas tabelas: Estudantes e Associações.
Nesse design, quando um aluno ingressa em seu primeiro clube, devemos adicioná-lo à tabela Estudantes, onde seu nome, sobrenome, endereço de e-mail e ano de nascimento são inseridos. Essa adição à tabela Estudantes gerará uma carteira de estudante. Agora, adicionaremos uma nova entrada para indicar que o aluno é um sócio específico do clube. Isso é feito adicionando um registro com a carteira de estudante e a ID do clube na tabela de Associações. Se esse aluno ingressar em um segundo clube, não precisaremos duplicar o nome, o e-mail e o ano de nascimento do aluno; em vez disso, só precisamos fazer outra inscrição na tabela de Associações da carteira de identidade do segundo clube e da carteira de estudante.
O design do banco de dados do Student Clubs também simplifica a alteração do design sem grandes modificações na estrutura existente. Por exemplo, se a equipe de design fosse solicitada a adicionar funcionalidade ao sistema para rastrear os conselheiros docentes dos clubes, poderíamos facilmente fazer isso adicionando uma tabela de orientadores do corpo docente (semelhante à tabela Estudantes) e, em seguida, adicionando um novo campo à tabela Clubes para conter a ID do orientador do corpo docente.
Tipos de dados
Ao definir os campos em uma tabela de banco de dados, devemos dar a cada campo um tipo de dados. Por exemplo, o campo Ano de Nascimento é um ano, então será um número, enquanto Nome será texto. A maioria dos bancos de dados modernos permite o armazenamento de vários tipos de dados diferentes. Alguns dos tipos de dados mais comuns estão listados aqui:
- Texto: para armazenar dados não numéricos breves, geralmente com menos de 256 caracteres. O designer do banco de dados pode identificar o tamanho máximo do texto.
- Número: para armazenar números. Geralmente, existem alguns tipos de números diferentes selecionados, dependendo do tamanho do maior número.
- Sim/Não: uma forma especial do tipo de dados numérico que tem (geralmente) um byte de comprimento, com 0 para “Não” ou “Falso” e 1 para “Sim” ou “Verdadeiro”.
- Data/Hora: uma forma especial do tipo de dados numérico pode ser interpretada como um número ou uma hora.
- Moeda: uma forma especial do tipo de dados numéricos que formata todos os valores com um indicador de moeda e duas casas decimais.
- Texto do parágrafo: esse tipo de dados permite texto com mais de 256 caracteres.
- Objeto: esse tipo de dados permite o armazenamento de dados que não podem ser inseridos por meio de teclados, como uma imagem ou um arquivo de música.
A importância de definir adequadamente o tipo de dados é melhorar a integridade dos dados e o local de armazenamento adequado. Precisamos definir adequadamente o tipo de dados de um campo, e um tipo de dado informa ao banco de dados quais funções podem ser executadas com os dados. Por exemplo, se quisermos realizar funções matemáticas com um dos campos, devemos informar ao banco de dados que o campo é um tipo de dados numérico. Portanto, se tivermos um campo armazenando o ano de nascimento, podemos subtrair o número armazenado nesse campo do ano atual para obter a idade.
A alocação de espaço de armazenamento para os dados definidos também deve ser identificada. Por exemplo, se o campo Nome for definido como um tipo de dados de texto (50), cinquenta caracteres serão alocados para cada nome que desejamos armazenar. No entanto, mesmo que o primeiro nome tenha apenas cinco caracteres, cinquenta caracteres (bytes) serão alocados. Embora isso possa não parecer grande coisa, se nossa tabela tiver 50.000 nomes, alocaremos 50 * 50.000 = 2.500.000 bytes para armazenamento desses valores. Pode ser prudente reduzir o tamanho do campo, para não desperdiçarmos espaço de armazenamento.