
2.4: Analisando descobertas
- Page ID
- 185722

Você sabia que, à medida que as vendas de sorvetes aumentam, o mesmo acontece com a taxa geral de criminalidade? É possível que se deliciar com seu sabor favorito de sorvete possa levar você a uma onda de crimes? Ou, depois de cometer um crime, você acha que pode decidir se presentear com um cone? Não há dúvida de que existe uma relação entre sorvete e crime (por exemplo, Harper, 2013), mas seria muito tolo decidir que uma coisa realmente causou a outra.
É muito mais provável que tanto as vendas de sorvetes quanto as taxas de criminalidade estejam relacionadas à temperatura externa. Quando a temperatura está quente, muitas pessoas saem de casa, interagindo umas com as outras, se irritando umas com as outras e, às vezes, cometendo crimes. Além disso, quando está quente lá fora, é mais provável que procuremos uma guloseima fresca, como sorvete. Como determinamos se realmente existe uma relação entre duas coisas? E quando há um relacionamento, como podemos discernir se ele é atribuível à coincidência ou causalidade?
Pesquisa correlacional
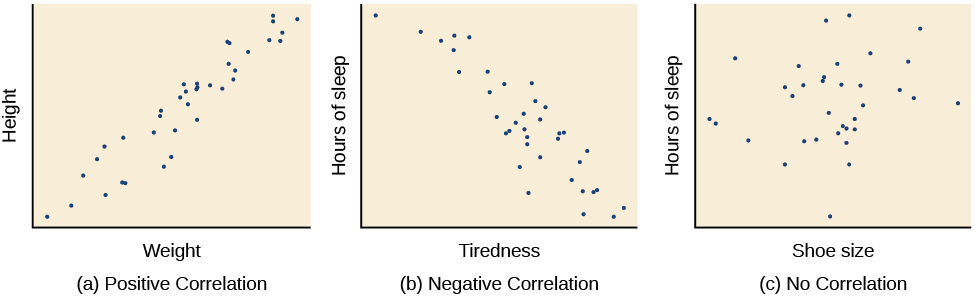
Correlação significa que há uma relação entre duas ou mais variáveis (como consumo de sorvete e crime), mas essa relação não implica necessariamente causa e efeito. Quando duas variáveis são correlacionadas, significa simplesmente que, à medida que uma variável muda, a outra também muda. Podemos medir a correlação calculando uma estatística conhecida como coeficiente de correlação. Um coeficiente de correlação é um número de -1 a +1 que indica a força e a direção da relação entre as variáveis. O coeficiente de correlação geralmente é representado pela letra r.
A parte numérica do coeficiente de correlação indica a força da relação. Quanto mais próximo o número estiver de 1 (seja negativo ou positivo), mais fortemente relacionadas serão as variáveis e mais previsíveis serão as mudanças em uma variável à medida que a outra variável mudar. Quanto mais próximo o número de zero, mais fraca é a relação e menos previsíveis se tornam as relações entre as variáveis. Por exemplo, um coeficiente de correlação de 0,9 indica uma relação muito mais forte do que um coeficiente de correlação de 0,3. Se as variáveis não estiverem relacionadas entre si, o coeficiente de correlação é 0. O exemplo acima sobre sorvete e crime é um exemplo de duas variáveis que podemos esperar que não tenham relação entre si.
O sinal — positivo ou negativo — do coeficiente de correlação indica a direção da relação (Figura 2.12). Uma correlação positiva significa que as variáveis se movem na mesma direção. Dito de outra forma, significa que, à medida que uma variável aumenta, a outra também aumenta e, inversamente, quando uma variável diminui, a outra também aumenta. Uma correlação negativa significa que as variáveis se movem em direções opostas. Se duas variáveis estiverem negativamente correlacionadas, uma diminuição em uma variável está associada a um aumento na outra e vice-versa.
O exemplo das taxas de sorvete e criminalidade é uma correlação positiva porque ambas as variáveis aumentam quando as temperaturas estão mais altas. Outros exemplos de correlações positivas são a relação entre a altura e o peso de um indivíduo ou a relação entre a idade de uma pessoa e o número de rugas. Pode-se esperar que exista uma correlação negativa entre o cansaço de alguém durante o dia e o número de horas que dormiu na noite anterior: a quantidade de sono diminui à medida que a sensação de cansaço aumenta. Em um exemplo real de correlação negativa, estudantes pesquisadores da Universidade de Minnesota descobriram uma correlação negativa fraca (r = -0,29) entre o número médio de dias por semana em que os alunos dormiam menos de 5 horas e seu GPA (Lowry, Dean, & Manders, 2010). Lembre-se de que uma correlação negativa não é o mesmo que nenhuma correlação. Por exemplo, provavelmente não encontraríamos correlação entre horas de sono e tamanho do sapato.
Conforme mencionado anteriormente, as correlações têm valor preditivo. Imagine que você faz parte do comitê de admissão de uma grande universidade. Você se depara com um grande número de inscrições, mas é capaz de acomodar apenas uma pequena porcentagem do pool de candidatos. Como você pode decidir quem deve ser admitido? Você pode tentar correlacionar o GPA universitário de seus alunos atuais com suas pontuações em testes padronizados, como o SAT ou o ACT. Ao observar quais correlações foram mais fortes para seus alunos atuais, você pode usar essas informações para prever o sucesso relativo dos estudantes que se inscreveram para admissão na universidade.
A correlação não indica causalidade
A pesquisa correlacional é útil porque nos permite descobrir a força e a direção das relações que existem entre duas variáveis. No entanto, a correlação é limitada porque estabelecer a existência de um relacionamento nos diz pouco sobre causa e efeito. Embora as variáveis às vezes sejam correlacionadas porque uma causa a outra, também pode ser que algum outro fator, uma variável de confusão, esteja realmente causando o movimento sistemático em nossas variáveis de interesse. No exemplo de sorvete/taxa de criminalidade mencionado anteriormente, a temperatura é uma variável de confusão que pode explicar a relação entre as duas variáveis.
Mesmo quando não podemos apontar para variáveis de confusão claras, não devemos supor que uma correlação entre duas variáveis implique que uma variável causa mudanças em outra. Isso pode ser frustrante quando uma relação de causa e efeito parece clara e intuitiva. Pense em nossa discussão sobre a pesquisa feita pela American Cancer Society e como seus projetos de pesquisa foram algumas das primeiras demonstrações da ligação entre tabagismo e câncer. Parece razoável supor que fumar causa câncer, mas se estivéssemos limitados à pesquisa correlacional, estaríamos ultrapassando nossos limites ao fazer essa suposição.
Infelizmente, as pessoas erroneamente fazem alegações de causalidade em função de correlações o tempo todo. Essas alegações são especialmente comuns em anúncios e notícias. Por exemplo, pesquisas recentes descobriram que pessoas que comem cereais regularmente atingem pesos mais saudáveis do que aquelas que raramente comem cereais (Frantzen, Treviño, Echon, Garcia-Dominic e DiMarco, 2013; Barton et al., 2005). Adivinhe como as empresas de cereais relatam essa descoberta. Comer cereais realmente faz com que um indivíduo mantenha um peso saudável ou existem outras explicações possíveis, como: alguém com peso saudável tem maior probabilidade de tomar um café da manhã saudável regularmente do que alguém obeso ou alguém que evita refeições na tentativa de fazer dieta (Figura 2). 13)? Embora a pesquisa correlacional seja inestimável na identificação de relações entre variáveis, uma grande limitação é a incapacidade de estabelecer causalidade. Os psicólogos querem fazer declarações sobre causa e efeito, mas a única maneira de fazer isso é conduzindo um experimento para responder a uma pergunta de pesquisa. A próxima seção descreve como os experimentos científicos incorporam métodos que eliminam ou controlam explicações alternativas, que permitem aos pesquisadores explorar como as mudanças em uma variável causam mudanças em outra variável.

Correlações ilusórias
A tentação de fazer declarações errôneas de causa e efeito com base em pesquisas correlacionais não é a única maneira pela qual tendemos a interpretar mal os dados. Também tendemos a cometer o erro de correlações ilusórias, especialmente com observações não sistemáticas. Correlações ilusórias, ou falsas correlações, ocorrem quando as pessoas acreditam que existem relações entre duas coisas quando não existe tal relacionamento. Uma correlação ilusória bem conhecida é o suposto efeito que as fases da lua têm no comportamento humano. Muitas pessoas afirmam apaixonadamente que o comportamento humano é afetado pela fase da lua e, especificamente, que as pessoas agem de forma estranha quando a lua está cheia (Figura 2.14).

Não há como negar que a lua exerce uma influência poderosa em nosso planeta. O fluxo e refluxo das marés do oceano estão fortemente ligados às forças gravitacionais da lua. Muitas pessoas acreditam, portanto, que é lógico que também sejamos afetados pela lua. Afinal, nossos corpos são em grande parte feitos de água. Uma meta-análise de quase 40 estudos demonstrou consistentemente, no entanto, que a relação entre a lua e nosso comportamento não existe (Rotton & Kelly, 1985). Embora possamos prestar mais atenção ao comportamento estranho durante toda a fase da lua, as taxas de comportamento estranho permanecem constantes durante todo o ciclo lunar.
Por que estamos tão aptos a acreditar em correlações ilusórias como essa? Freqüentemente, lemos ou ouvimos sobre eles e simplesmente aceitamos as informações como válidas. Ou temos um palpite sobre como algo funciona e, em seguida, procuramos evidências para apoiar esse palpite, ignorando as evidências que nos dizem que nosso palpite é falso; isso é conhecido como viés de confirmação. Outras vezes, encontramos correlações ilusórias com base nas informações que vêm mais facilmente à mente, mesmo que essas informações sejam severamente limitadas. E embora possamos nos sentir confiantes de que podemos usar esses relacionamentos para entender e prever melhor o mundo ao nosso redor, correlações ilusórias podem ter desvantagens significativas. Por exemplo, pesquisas sugerem que correlações ilusórias — nas quais certos comportamentos são atribuídos de forma imprecisa a certos grupos — estão envolvidas na formação de atitudes preconceituosas que podem, em última instância, levar a comportamentos discriminatórios (Fiedler, 2004).
Causalidade: conduzindo experimentos e usando os dados
Como você aprendeu, a única maneira de estabelecer que existe uma relação de causa e efeito entre duas variáveis é conduzindo um experimento científico. O experimento tem um significado diferente no contexto científico do que na vida cotidiana. Nas conversas do dia a dia, costumamos usá-lo para descrever experimentar algo pela primeira vez, como experimentar um novo estilo de cabelo ou uma nova comida. No entanto, no contexto científico, um experimento tem requisitos precisos para design e implementação.
A hipótese experimental
Para realizar um experimento, um pesquisador deve ter uma hipótese específica a ser testada. Como você aprendeu, as hipóteses podem ser formuladas por meio da observação direta do mundo real ou após uma análise cuidadosa de pesquisas anteriores. Por exemplo, se você acha que o uso da tecnologia na sala de aula tem impactos negativos no aprendizado, você basicamente formulou uma hipótese, a saber, que o uso da tecnologia na sala de aula deve ser limitado porque diminui o aprendizado. Como você pode ter chegado a essa hipótese em particular? Você deve ter notado que seus colegas que fazem anotações em seus laptops têm um desempenho mais baixo nos exames de classe do que aqueles que fazem anotações manualmente ou aqueles que recebem uma aula por meio de um programa de computador versus por meio de um professor presencial têm níveis diferentes de desempenho quando testados (Figura 2.15). ).
Esses tipos de observações pessoais são o que muitas vezes nos levam a formular uma hipótese específica, mas não podemos usar observações pessoais limitadas e evidências anedóticas para testar rigorosamente nossa hipótese. Em vez disso, para descobrir se os dados do mundo real apoiam nossa hipótese, precisamos realizar um experimento.
Projetando um experimento
O desenho experimental mais básico envolve dois grupos: o grupo experimental e o grupo controle. Os dois grupos são projetados para serem iguais, exceto por uma diferença: manipulação experimental. O grupo experimental recebe a manipulação experimental — ou seja, o tratamento ou a variável que está sendo testada (neste caso, o uso da tecnologia) — e o grupo de controle não. Como a manipulação experimental é a única diferença entre os grupos experimental e controle, podemos ter certeza de que qualquer diferença entre os dois se deve à manipulação experimental e não ao acaso.
Em nosso exemplo de como o uso da tecnologia deve ser limitado na sala de aula, temos o grupo experimental aprender álgebra usando um programa de computador e depois testar seu aprendizado. Medimos o aprendizado em nosso grupo de controle após o ensino de álgebra por um professor em uma sala de aula tradicional. É importante que o grupo controle seja tratado de forma semelhante ao grupo experimental, com a exceção de que o grupo controle não recebe a manipulação experimental.
Também precisamos definir com precisão, ou operacionalizar, como medimos o aprendizado de álgebra. Uma definição operacional é uma descrição precisa de nossas variáveis e é importante para permitir que outras pessoas entendam exatamente como e o que um pesquisador mede em um experimento específico. Ao operacionalizar a aprendizagem, podemos optar por analisar o desempenho em um teste que abrange o material no qual os indivíduos foram ensinados pelo professor ou pelo programa de computador. Também podemos pedir aos nossos participantes que resumam as informações que acabaram de ser apresentadas de alguma forma. O que quer que determinemos, é importante operacionalizar o aprendizado de forma que qualquer pessoa que ouça sobre nosso estudo pela primeira vez saiba exatamente o que queremos dizer com aprendizado. Isso ajuda as pessoas a interpretar nossos dados, bem como a capacidade de repetir nosso experimento, caso optem por fazê-lo.
Depois de operacionalizar o que é considerado uso da tecnologia e o que é considerado aprendizado nos participantes do experimento, precisamos estabelecer como executaremos nosso experimento. Nesse caso, podemos fazer com que os participantes passem 45 minutos aprendendo álgebra (seja por meio de um programa de computador ou com um professor presencial de matemática) e, em seguida, façam um teste no material abordado durante os 45 minutos.
Idealmente, as pessoas que pontuam os testes não sabem quem foi designado para o grupo experimental ou de controle, a fim de controlar o viés do experimentador. O viés do experimentador se refere à possibilidade de que as expectativas de um pesquisador possam distorcer os resultados do estudo. Lembre-se de que conduzir um experimento exige muito planejamento, e as pessoas envolvidas no projeto de pesquisa têm grande interesse em apoiar suas hipóteses. Se os observadores soubessem qual criança estava em qual grupo, isso poderia influenciar a forma como eles interpretam respostas ambíguas, como caligrafia desleixada ou pequenos erros computacionais. Ao sermos cegos para qual criança está em qual grupo, nos protegemos contra esses preconceitos. Essa situação é um estudo cego, o que significa que um dos grupos (participantes) não sabe em qual grupo eles estão (experimento ou grupo de controle), enquanto o pesquisador que desenvolveu o experimento sabe quais participantes estão em cada grupo.
Em um estudo duplo-cego, tanto os pesquisadores quanto os participantes estão cegos para tarefas em grupo. Por que um pesquisador gostaria de realizar um estudo em que ninguém sabe quem está em qual grupo? Porque, ao fazer isso, podemos controlar as expectativas do experimentador e do participante. Se você está familiarizado com a frase efeito placebo, já tem alguma ideia de por que essa é uma consideração importante. O efeito placebo ocorre quando as expectativas ou crenças das pessoas influenciam ou determinam sua experiência em uma determinada situação. Em outras palavras, simplesmente esperar que algo aconteça pode realmente fazer com que isso aconteça.
O efeito placebo é comumente descrito em termos de testar a eficácia de um novo medicamento. Imagine que você trabalha em uma empresa farmacêutica e acha que tem um novo medicamento eficaz no tratamento da depressão. Para demonstrar que seu medicamento é eficaz, você realiza um experimento com dois grupos: o grupo experimental recebe o medicamento e o grupo de controle não. Mas você não quer que os participantes saibam se receberam o medicamento ou não.
Por que isso? Imagine que você participa deste estudo e acabou de tomar uma pílula que acha que vai melhorar seu humor. Como você espera que a pílula tenha um efeito, você pode se sentir melhor simplesmente porque tomou a pílula e não por causa de qualquer medicamento realmente contido na pílula - esse é o efeito placebo.
Para garantir que qualquer efeito no humor seja devido ao medicamento e não às expectativas, o grupo de controle recebe um placebo (neste caso, uma pílula de açúcar). Agora todo mundo toma uma pílula e, mais uma vez, nem o pesquisador nem os participantes do experimento sabem quem recebeu a droga e quem tomou a pílula de açúcar. Quaisquer diferenças de humor entre os grupos experimental e controle agora podem ser atribuídas ao medicamento em si, e não ao viés do experimentador ou às expectativas dos participantes (Figura 2.16).
Variáveis independentes e dependentes
Em um experimento de pesquisa, nos esforçamos para estudar se mudanças em uma coisa causam mudanças em outra. Para conseguir isso, devemos prestar atenção a duas variáveis importantes, ou coisas que podem ser alteradas, em qualquer estudo experimental: a variável independente e a variável dependente. Uma variável independente é manipulada ou controlada pelo experimentador. Em um estudo experimental bem desenhado, a variável independente é a única diferença importante entre os grupos experimental e controle. Em nosso exemplo de como o uso da tecnologia na sala de aula afeta o aprendizado, a variável independente é o tipo de aprendizado dos participantes do estudo (Figura 2.17). Uma variável dependente é o que o pesquisador mede para ver quanto efeito a variável independente teve. Em nosso exemplo, a variável dependente é o aprendizado exibido por nossos participantes.
Esperamos que a variável dependente mude em função da variável independente. Em outras palavras, a variável dependente depende da variável independente. Uma boa maneira de pensar sobre a relação entre as variáveis independentes e dependentes é com esta pergunta: Que efeito a variável independente tem na variável dependente? Voltando ao nosso exemplo, qual é o efeito de aprender uma aula por meio de um programa de computador versus por meio de um instrutor presencial?
Seleção e atribuição de participantes experimentais
Agora que nosso estudo foi elaborado, precisamos obter uma amostra de indivíduos para incluir em nosso experimento. Nosso estudo envolve participantes humanos, então precisamos determinar quem incluir. Os participantes são sujeitos da pesquisa psicológica e, como o nome indica, indivíduos envolvidos na pesquisa psicológica participam ativamente do processo. Freqüentemente, projetos de pesquisa psicológica contam com estudantes universitários para atuar como participantes. De fato, a grande maioria das pesquisas nos subcampos da psicologia historicamente envolveu estudantes como participantes da pesquisa (Sears, 1986; Arnett, 2008). Mas os estudantes universitários são realmente representativos da população em geral? Os estudantes universitários tendem a ser mais jovens, mais educados, mais liberais e menos diversificados do que a população em geral. Embora usar estudantes como cobaias seja uma prática aceita, confiar em um grupo tão limitado de participantes da pesquisa pode ser problemático porque é difícil generalizar as descobertas para a população em geral.
Nosso experimento hipotético envolve estudantes do ensino médio e devemos primeiro gerar uma amostra de estudantes. As amostras são usadas porque as populações geralmente são grandes demais para envolver razoavelmente cada membro em nosso experimento específico (Figura 2.18). Se possível, devemos usar uma amostra aleatória (existem outros tipos de amostras, mas para os fins deste capítulo, vamos nos concentrar em amostras aleatórias). Uma amostra aleatória é um subconjunto de uma população maior na qual cada membro da população tem a mesma chance de ser selecionado. Amostras aleatórias são preferidas porque, se a amostra for grande o suficiente, podemos ter certeza razoável de que os indivíduos participantes são representativos da população maior. Isso significa que as porcentagens de características na amostra — sexo, etnia, nível socioeconômico e quaisquer outras características que possam afetar os resultados — estão próximas dessas porcentagens na população maior.
Em nosso exemplo, digamos que decidimos que nossa população de interesse são estudantes de álgebra. Mas todos os estudantes de álgebra são uma população muito grande, então precisamos ser mais específicos; em vez disso, podemos dizer que nossa população de interesse é toda estudante de álgebra em uma determinada cidade. Devemos incluir estudantes de várias faixas de renda, situações familiares, raças, etnias, religiões e áreas geográficas da cidade. Com essa população mais gerenciável, podemos trabalhar com as escolas locais na seleção de uma amostra aleatória de cerca de 200 estudantes de álgebra dos quais queremos participar do nosso experimento.
Em resumo, como não podemos testar todos os estudantes de álgebra em uma cidade, queremos encontrar um grupo de cerca de 200 que reflita a composição dessa cidade. Com um grupo representativo, podemos generalizar nossas descobertas para a população maior sem medo de que nossa amostra seja tendenciosa de alguma forma.

Agora que temos uma amostra, a próxima etapa do processo experimental é dividir os participantes em grupos experimentais e de controle por meio de atribuição aleatória. Com a atribuição aleatória, todos os participantes têm a mesma chance de serem designados para qualquer um dos grupos. Existe um software estatístico que atribuirá aleatoriamente cada um dos estudantes de álgebra da amostra ao grupo experimental ou ao grupo de controle.
A atribuição aleatória é fundamental para o design experimental de som. Com amostras suficientemente grandes, a atribuição aleatória torna improvável que haja diferenças sistemáticas entre os grupos. Então, por exemplo, seria muito improvável que tivéssemos um grupo composto inteiramente por homens, uma determinada identidade étnica ou uma determinada ideologia religiosa. Isso é importante porque, se os grupos fossem sistematicamente diferentes antes do início do experimento, não saberíamos a origem de nenhuma diferença que encontramos entre os grupos: as diferenças eram preexistentes ou foram causadas pela manipulação da variável independente? A atribuição aleatória nos permite supor que quaisquer diferenças observadas entre grupos experimentais e de controle resultam da manipulação da variável independente.
Questões a considerar
Embora os experimentos permitam que os cientistas façam alegações de causa e efeito, eles não estão isentos de problemas. Experimentos verdadeiros exigem que o experimentador manipule uma variável independente, e isso pode complicar muitas questões que os psicólogos podem querer abordar. Por exemplo, imagine que você queira saber qual efeito o sexo (a variável independente) tem na memória espacial (a variável dependente). Embora você possa certamente procurar diferenças entre homens e mulheres em uma tarefa que explora a memória espacial, você não pode controlar diretamente o sexo de uma pessoa. Categorizamos esse tipo de abordagem de pesquisa como quase experimental e reconhecemos que não podemos fazer alegações de causa e efeito nessas circunstâncias.
Os experimentadores também estão limitados por restrições éticas. Por exemplo, você não seria capaz de conduzir um experimento desenvolvido para determinar se sofrer abuso quando criança leva a níveis mais baixos de autoestima entre adultos. Para realizar esse experimento, você precisaria atribuir aleatoriamente alguns participantes do experimento a um grupo que recebe abuso, e esse experimento não seria ético.
Interpretando descobertas experimentais
Depois que os dados são coletados dos grupos experimental e de controle, uma análise estatística é conduzida para descobrir se há diferenças significativas entre os dois grupos. Uma análise estatística determina a probabilidade de qualquer diferença encontrada ser devida ao acaso (e, portanto, não significativa). Por exemplo, se um experimento for feito sobre a eficácia de um suplemento nutricional e aqueles que tomam uma pílula placebo (e não o suplemento) tiverem o mesmo resultado que aqueles que tomam o suplemento nutricional, o experimento mostrou que o suplemento nutricional não é eficaz. Geralmente, os psicólogos consideram as diferenças estatisticamente significativas se houver menos de cinco por cento de chance de observá-las se os grupos não diferirem realmente uns dos outros. Dito de outra forma, os psicólogos querem limitar as chances de fazer afirmações “falsas positivas” a cinco por cento ou menos.
A maior força dos experimentos é a capacidade de afirmar que quaisquer diferenças significativas nas descobertas são causadas pela variável independente. Isso ocorre porque a seleção aleatória, a atribuição aleatória e um design que limita os efeitos do viés do experimentador e da expectativa do participante devem criar grupos que sejam semelhantes em composição e tratamento. Portanto, qualquer diferença entre os grupos é atribuível à variável independente, e agora podemos finalmente fazer uma declaração causal. Se percebermos que assistir a um programa de televisão violento resulta em um comportamento mais violento do que assistir a um programa não violento, podemos afirmar com segurança que assistir programas de televisão violentos causa um aumento na exibição de comportamento violento.
Pesquisa de relatórios
Quando os psicólogos concluem um projeto de pesquisa, eles geralmente querem compartilhar suas descobertas com outros cientistas. A Associação Americana de Psicologia (APA) publica um manual detalhando como escrever um artigo para submissão a periódicos científicos. Ao contrário de um artigo que pode ser publicado em uma revista como a Psychology Today, que tem como alvo um público geral interessado em psicologia, os periódicos científicos geralmente publicam artigos de periódicos revisados por pares voltados para um público de profissionais e acadêmicos que estão ativamente envolvidos na própria pesquisa.
Um artigo de jornal revisado por pares é lido por vários outros cientistas (geralmente anonimamente) com experiência no assunto. Esses pareceristas fornecem feedback — tanto para o autor quanto para o editor da revista — sobre a qualidade do rascunho. Os revisores de pares buscam uma forte justificativa para a pesquisa que está sendo descrita, uma descrição clara de como a pesquisa foi conduzida e evidências de que a pesquisa foi conduzida de maneira ética. Eles também buscam falhas no desenho, nos métodos e nas análises estatísticas do estudo. Eles verificam se as conclusões tiradas pelos autores parecem razoáveis, dadas as observações feitas durante a pesquisa. Os revisores também comentam sobre o valor da pesquisa para o avanço do conhecimento da disciplina. Isso ajuda a evitar a duplicação desnecessária dos resultados da pesquisa na literatura científica e, até certo ponto, garante que cada artigo de pesquisa forneça novas informações. Em última análise, o editor da revista compilará todos os comentários dos revisores e determinará se o artigo será publicado em seu estado atual (uma ocorrência rara), publicado com revisões ou se não será aceito para publicação.
A revisão por pares fornece algum grau de controle de qualidade para pesquisas psicológicas. Estudos mal concebidos ou executados podem ser eliminados, e até mesmo pesquisas bem projetadas podem ser aprimoradas com as revisões sugeridas. A revisão por pares também garante que a pesquisa seja descrita com clareza suficiente para permitir que outros cientistas a reproduzam, o que significa que eles podem repetir o experimento usando amostras diferentes para determinar a confiabilidade. Às vezes, as replicações envolvem medidas adicionais que expandem a descoberta original. De qualquer forma, cada replicação serve para fornecer mais evidências para apoiar os resultados da pesquisa original. Replicações bem-sucedidas de pesquisas publicadas tornam os cientistas mais aptos a adotar essas descobertas, enquanto falhas repetidas tendem a colocar em dúvida a legitimidade do artigo original e levar os cientistas a procurar outro lugar. Por exemplo, seria um grande avanço na área médica se um estudo publicado indicasse que o uso de um novo medicamento ajudou as pessoas a atingir um peso saudável sem mudar sua dieta. Mas se outros cientistas não conseguissem replicar os resultados, as alegações do estudo original seriam questionadas.
Nos últimos anos, tem havido uma preocupação crescente com uma “crise de replicação” que afetou vários campos científicos, incluindo a psicologia. Alguns dos estudos e cientistas mais conhecidos produziram pesquisas que não foram replicadas por outros (conforme discutido em Shrout & Rodgers, 2018). Na verdade, até mesmo uma famosa cientista ganhadora do Prêmio Nobel retirou recentemente um artigo publicado porque teve dificuldade em replicar seus resultados (a cientista vencedora do Prêmio Nobel Frances Arnold retira o artigo, 3 de janeiro de 2020). Esses tipos de resultados levaram alguns cientistas a começarem a trabalhar juntos e de forma mais aberta, e alguns argumentam que a atual “crise” está, na verdade, melhorando as formas pelas quais a ciência é conduzida e como seus resultados são compartilhados com outras pessoas (Aschwanden, 2018).
Alguns cientistas alegaram que as vacinas infantis de rotina fazem com que algumas crianças desenvolvam autismo e, de fato, várias publicações revisadas por pares publicaram pesquisas fazendo essas afirmações. Desde os relatórios iniciais, pesquisas epidemiológicas em grande escala sugeriram que as vacinas não são responsáveis por causar autismo e que é muito mais seguro vacinar seu filho do que não. Além disso, vários dos estudos originais que fizeram essa afirmação foram retirados desde então.
Um trabalho publicado pode ser rescindido quando os dados são questionados devido a falsificação, fabricação ou sérios problemas de projeto de pesquisa. Uma vez rescindida, a comunidade científica é informada de que há sérios problemas com a publicação original. As retratações podem ser iniciadas pelo pesquisador que liderou o estudo, pelos colaboradores da pesquisa, pela instituição que empregou o pesquisador ou pelo conselho editorial da revista na qual o artigo foi originalmente publicado. No caso vacina-autismo, a retração foi feita devido a um significativo conflito de interesses no qual o pesquisador principal tinha interesse financeiro em estabelecer uma ligação entre vacinas infantis e autismo (Offit, 2008). Infelizmente, os estudos iniciais receberam tanta atenção da mídia que muitos pais em todo o mundo hesitaram em vacinar seus filhos (Figura 2.19). A confiança contínua em tais estudos desmascarados tem consequências significativas. Por exemplo, entre janeiro e outubro de 2019, houve 22 surtos de sarampo nos Estados Unidos e mais de mil casos de indivíduos contraindo sarampo (Patel et al., 2019). Provavelmente, isso se deve aos movimentos antivacinação decorrentes da pesquisa desmascarada. Para obter mais informações sobre como a história da vacina/autismo se desenrolou, bem como as repercussões dessa história, dê uma olhada no livro de Paul Offit, Autism's False Prophets: Bad Science, Risky Medicine, and the Search for a Cure.
Confiabilidade e validade
Confiabilidade e validade são duas considerações importantes que devem ser feitas com qualquer tipo de coleta de dados. Confiabilidade se refere à capacidade de produzir consistentemente um determinado resultado. No contexto da pesquisa psicológica, isso significaria que quaisquer instrumentos ou ferramentas usadas para coletar dados o fazem de maneiras consistentes e reproduzíveis. Existem vários tipos diferentes de confiabilidade. Algumas delas incluem confiabilidade entre avaliadores (o grau em que dois ou mais observadores diferentes concordam sobre o que foi observado), consistência interna (o grau em que diferentes itens em uma pesquisa que medem a mesma coisa se correlacionam entre si) e confiabilidade teste-reteste (o grau em que o os resultados de uma medida específica permanecem consistentes em várias administrações).
Infelizmente, ser consistente na medição não significa necessariamente que você mediu algo corretamente. Para ilustrar esse conceito, considere uma balança de cozinha que seria usada para medir o peso do cereal que você come pela manhã. Se a balança não estiver devidamente calibrada, ela pode subestimar ou superestimar consistentemente a quantidade de cereal que está sendo medida. Embora a balança seja altamente confiável na produção de resultados consistentes (por exemplo, a mesma quantidade de cereal despejada na balança produz a mesma leitura a cada vez), esses resultados estão incorretos. É aqui que a validade entra em jogo. A validade se refere à medida em que um determinado instrumento ou ferramenta mede com precisão o que deveria medir e, mais uma vez, existem várias maneiras pelas quais a validade pode ser expressa. Validade ecológica (o grau em que os resultados da pesquisa se generalizam para aplicações do mundo real), validade de construção (o grau em que uma determinada variável realmente captura ou mede o que se pretende medir) e validade facial (o grau em que uma determinada variável parece válida na superfície) são apenas alguns tipos que os pesquisadores consideram. Embora qualquer medida válida seja necessariamente confiável, o inverso não é necessariamente verdadeiro. Os pesquisadores se esforçam para usar instrumentos que sejam altamente confiáveis e válidos.
Testes padronizados como o SAT e o ACT devem medir a aptidão de um indivíduo para uma educação universitária, mas quão confiáveis e válidos são esses testes? Pesquisas conduzidas pelo College Board sugerem que as pontuações no SAT têm alta validade preditiva para o GPA dos estudantes universitários do primeiro ano (Kobrin, Patterson, Shaw, Mattern e Barbuti, 2008). Nesse contexto, a validade preditiva se refere à capacidade do teste de prever efetivamente o GPA de calouros da faculdade. Dado que muitas instituições de ensino superior exigem o SAT ou o ACT para admissão, esse alto grau de validade preditiva pode ser reconfortante.
No entanto, a ênfase colocada nas notas do SAT ou ACT nas admissões em faculdades gerou alguma controvérsia em várias frentes. Por um lado, alguns pesquisadores afirmam que esses testes são tendenciosos e colocam os estudantes de minorias em desvantagem e reduzem injustamente a probabilidade de serem admitidos em uma faculdade (Santelices & Wilson, 2010). Além disso, algumas pesquisas sugeriram que a validade preditiva desses testes é extremamente exagerada na forma como eles são capazes de prever o GPA de estudantes universitários do primeiro ano. De fato, foi sugerido que a validade preditiva do SAT pode ser superestimada em até 150% (Rothstein, 2004). Muitas instituições de ensino superior estão começando a considerar não enfatizar a importância das notas do SAT na tomada de decisões de admissão (Rimer, 2008).
Exemplos recentes de escândalos de trapaça de alto perfil, tanto no país quanto no exterior, só aumentaram o escrutínio sobre esses tipos de testes e, em março de 2019, mais de 1000 instituições de ensino superior relaxaram ou eliminaram os requisitos para testes SAT ou ACT para admissões ( Strauss, 2019, 19 de março).