
3.2 : Synthèse des données - Statistiques descriptives
- Page ID
- 167860

Comment synthétisez-vous les données ?
Les données sont résumées de deux manières principales : des calculs récapitulatifs et des visualisations récapitulatives
Calculs : quels types de mesures sont utilisés ?
Pour pouvoir interpréter les modèles des données, les données brutes doivent d'abord être manipulées et résumées en deux catégories de mesures : les mesures de la tendance centrale et les mesures de la variabilité. Ces deux catégories de mesures résument la première étape de la recherche scientifique, à savoir les statistiques descriptives.
Mesures de la tendance centrale (centre) — Fournit des informations sur la façon dont les données se regroupent autour d'une valeur moyenne unique. Deux mesures du centre sont utilisées le plus souvent dans les enquêtes biologiques :
- Moyenne (moyenne) — Somme de toutes les valeurs individuelles divisée par le nombre total de valeurs dans l'échantillon/la population. Il s'agit de la mesure du centre la plus couramment utilisée sous une distribution symétrique et elle est sensible aux valeurs aberrantes.
- Médiane : valeur médiane lorsque l'ensemble de données est classé par ordre séquentiel (du plus haut au plus bas). Ceci est couramment utilisé lorsque les données sont asymétriques et résistent aux valeurs aberrantes.
Mesures de la variabilité (dispersion) — Décrit le degré de dispersion ou de dispersion des données. Deux mesures principales de la propagation sont utilisées dans les enquêtes biologiques :
- Plage : quantifie la distance entre les valeurs de données les plus grandes et les plus petites.
- Écart type : quantifie la variation ou la dispersion par rapport à la moyenne d'un ensemble de données. Un écart type faible indique que les données ont tendance à être très proches de la moyenne ; un écart type élevé indique que les points de données sont répartis sur une large plage de valeurs. Ce calcul est sensible aux valeurs aberrantes.
- Erreur type : quantifie la variation des moyennes à partir de plusieurs ensembles de données ou d'une distribution d'échantillon de votre jeu de données d'origine.
Visualisation des données : comment sont utilisés les tableaux et les graphiques ?
Une fois que toutes les statistiques descriptives souhaitées ont été calculées, elles sont généralement résumées visuellement sous forme de tableau ou de graphique.
Tableaux :
Un tableau est un ensemble de valeurs de données organisées en colonnes et en lignes. En général, les colonnes englobent une vaste catégorie de données et les lignes en englobent une autre. Au sein de chaque grande catégorie, il existe des sous-catégories qui déterminent le nombre de colonnes et de lignes du tableau. Les tableaux sont utilisés à la fois pour collecter et résumer les données. Toutefois, la plupart du temps, lorsque les tableaux sont présentés, il s'agit de données résumées et non de données brutes. Bien que les tableaux permettent de présenter les données résumées de manière ordonnée, la plupart des utilisateurs préfèrent les traduire en un outil de visualisation des données plus puissant, un graphique.
Graphiques :
Un graphique est un diagramme montrant la relation entre des quantités variables, généralement de deux variables, chacune étant mesurée le long d'une paire d'axes à angle droit. Les graphiques peuvent ressembler à un graphique ou à un dessin. La plupart des graphiques utilisent des barres, des lignes ou des parties de cercle pour afficher les données. Cependant, il arrive parfois que des graphiques soient superposés sur des cartes pour afficher également l'emplacement géographique, ou qu'ils soient même animés pour être interactifs.
Principales catégories de types de graphes :
- Circle/Pie : graphique circulaire divisé en tranches pour illustrer les proportions numériques. Dans un diagramme circulaire, la longueur de l'arc de chaque tranche (et par conséquent son angle central et sa surface) est proportionnelle à la quantité qu'elle représente. Bien qu'il soit nommé pour sa ressemblance avec une tarte tranchée, il existe des variations dans la façon dont il peut être présenté.
- Ligne — Type de graphique qui affiche des informations sous la forme d'une série de points de données appelés « marqueurs » reliés par des segments de ligne droite. Il s'agit d'un type de graphique de base courant dans de nombreux domaines. Il est similaire à un nuage de points, sauf que les points de mesure sont ordonnés (généralement selon leur valeur sur l'axe X) et joints par des segments de ligne droite. Un graphique linéaire est souvent utilisé pour visualiser une tendance des données sur des intervalles de temps (une série chronologique). La ligne est donc souvent tracée de manière chronologique.
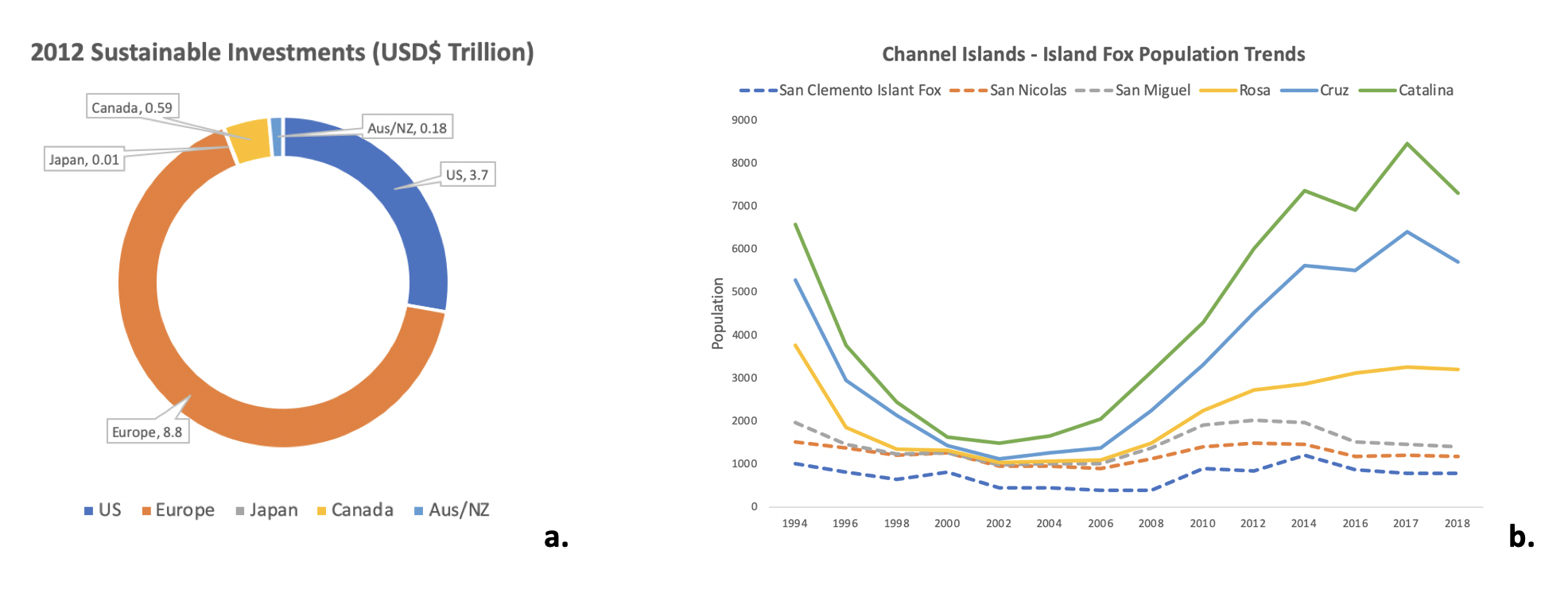
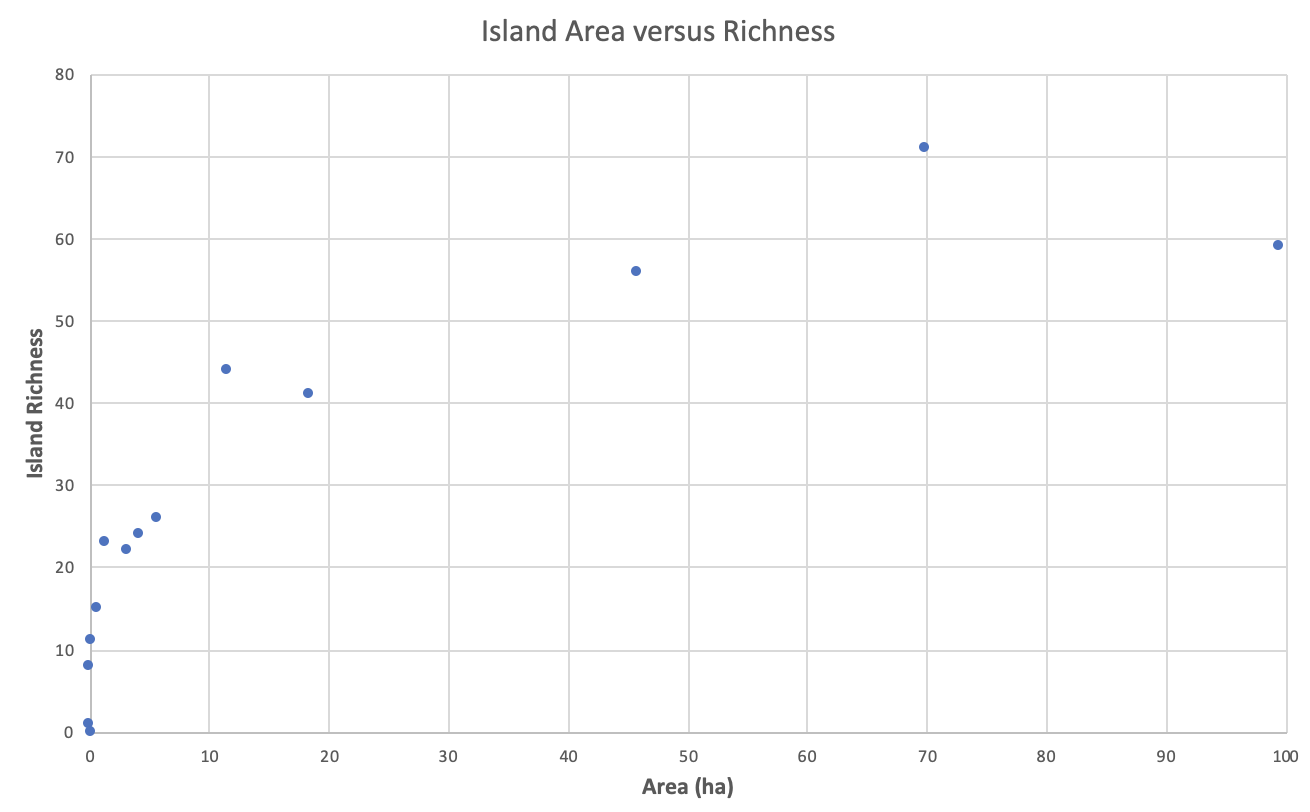
- Diagramme de dispersion : graphique dans lequel les valeurs de deux variables sont tracées le long des axes horizontal et vertical, le motif des points résultants révélant toute corrélation prédéfinie. Les données sont affichées sous la forme d'un ensemble de points, chacun ayant la valeur d'une variable déterminant la position sur l'axe horizontal et la valeur de l'autre variable déterminant la position sur l'axe vertical.
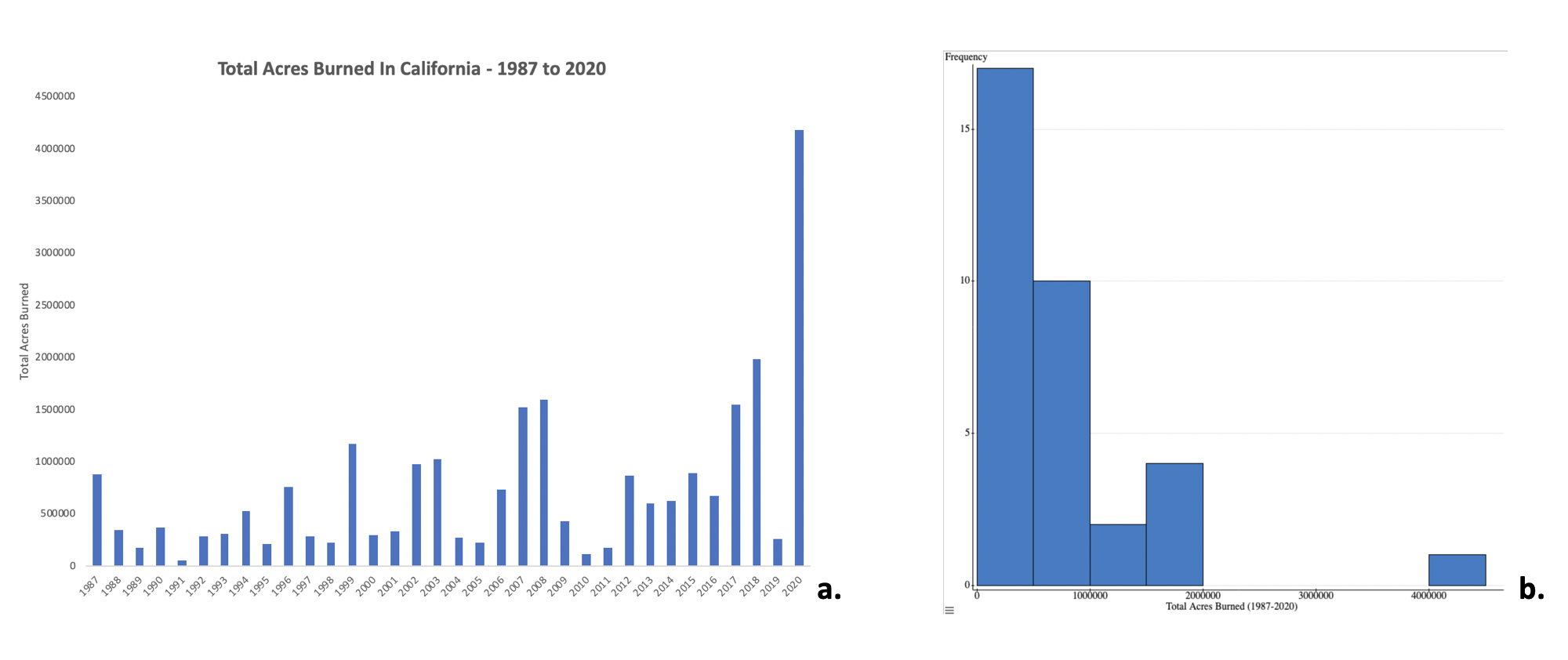
- Barre : diagramme ou graphique qui présente des données catégorielles avec des barres rectangulaires dont la hauteur ou la longueur est proportionnelle aux valeurs qu'elles représentent. Les barres peuvent être tracées verticalement ou horizontalement.
- Histogramme : représentation approximative de la distribution des données numériques. Pour créer un histogramme, la première étape consiste à « classer » (ou « regrouper ») la plage de valeurs, c'est-à-dire à diviser l'ensemble de la plage de valeurs en une série d'intervalles, puis à compter le nombre de valeurs comprises dans chaque intervalle. Les cellules sont généralement spécifiées sous la forme d'intervalles consécutifs et ne se chevauchant pas d'une variable. Les cases (intervalles) doivent être adjacentes (c'est-à-dire qu'il n'y a pas d'espace entre elles, comme c'est le cas dans les graphiques à barres) et sont souvent (mais pas obligatoirement) de taille égale. Si les compartiments sont de taille égale, un rectangle est érigé au-dessus du bac avec une hauteur proportionnelle à la fréquence, c'est-à-dire au nombre de caisses dans chaque compartiment.
Attribution
Rachel Schleiger (CC-BY-NC)