
3.2: Resumindo os dados - Estatísticas descritivas
- Page ID
- 172655

Como você resume os dados?
Os dados são resumidos de duas formas principais: cálculos resumidos e visualizações resumidas
Cálculos: Que tipos de medidas são usadas?
Para poder interpretar padrões nos dados, os dados brutos devem primeiro ser manipulados e resumidos em duas categorias de medidas: medidas de tendência central e medidas de variabilidade. Essas duas categorias de medidas resumem a primeira etapa da investigação científica, a estatística descritiva.
Medidas de tendência central (centro) — Fornece informações sobre como os dados se agrupam em torno de um único valor médio. Existem duas medidas de centro usadas com mais frequência na investigação biológica:
- Média (média) — Soma de todos os valores individuais dividida pelo número total de valores na amostra/população. Essa é a medida mais comumente usada do centro sob distribuição simétrica e é sensível a valores atípicos.
- Mediana — O valor médio quando o conjunto de dados é ordenado na classificação sequencial (da maior para a mais baixa). Isso é comumente usado quando os dados estão distorcidos e resistentes a valores atípicos.
Medidas de variabilidade (dispersão) — Descreve a dispersão ou dispersão dos dados. Existem duas medidas principais de propagação usadas na investigação biológica:
- Intervalo — Quantifica a distância entre os maiores e os menores valores de dados.
- Desvio padrão — Quantifica a variação ou dispersão da média de um conjunto de dados. Um desvio padrão baixo indica que os dados tendem a estar muito próximos da média; um desvio padrão alto indica que os pontos de dados estão espalhados por uma grande variedade de valores. Esse cálculo é sensível a valores atípicos.
- Erro padrão — Quantifica a variação nas médias de vários conjuntos de dados ou uma distribuição de amostra do seu conjunto de dados original.
Visualização dos dados: Como as tabelas e os gráficos são usados?
Depois que todas as estatísticas descritivas desejadas são calculadas, elas normalmente são resumidas visualmente em uma tabela ou gráfico.
Tabelas:
Uma tabela é um conjunto de valores de dados organizados em colunas e linhas. Normalmente, as colunas abrangem uma ampla categoria de dados e as linhas abrangem outra. Dentro de cada categoria ampla, há subcategorias que determinam em quantas colunas e linhas a tabela consiste. As tabelas são usadas para coletar e resumir dados. No entanto, na maioria das vezes, quando as tabelas são apresentadas, elas consistem em dados resumidos, não em dados brutos. Embora as tabelas permitam que os dados resumidos sejam apresentados de forma ordenada, a maioria das pessoas prefere traduzir as tabelas para a ferramenta de visualização de dados mais poderosa, um gráfico.
Gráficos:
Um gráfico é um diagrama que mostra a relação entre quantidades variáveis, normalmente de duas variáveis, cada uma medida ao longo de um par de eixos em ângulos retos. Os gráficos podem parecer um gráfico ou desenho. A maioria dos gráficos usa barras, linhas ou partes de um círculo para exibir dados. No entanto, às vezes há quando os gráficos são sobrepostos em cima dos mapas para também exibir a localização geográfica, ou até mesmo animados para serem interativos.
Principais categorias de tipos de gráficos:
- Círculo/Pizza — Um gráfico circular dividido em fatias para ilustrar a proporção numérica. Em um gráfico circular, o comprimento do arco de cada fatia (e, consequentemente, seu ângulo central e área) é proporcional à quantidade que ela representa. Embora tenha o nome de sua semelhança com uma torta que foi fatiada, existem variações na forma como ela pode ser apresentada.
- Linha — Um tipo de gráfico que exibe informações como uma série de pontos de dados chamados “marcadores” conectados por segmentos de linha reta. É um tipo básico de gráfico comum em muitos campos. É semelhante a um gráfico de dispersão, exceto que os pontos de medição são ordenados (normalmente pelo valor do eixo x) e unidos com segmentos de linha reta. Um gráfico de linhas é frequentemente usado para visualizar uma tendência nos dados em intervalos de tempo - uma série temporal - portanto, a linha geralmente é desenhada cronologicamente.
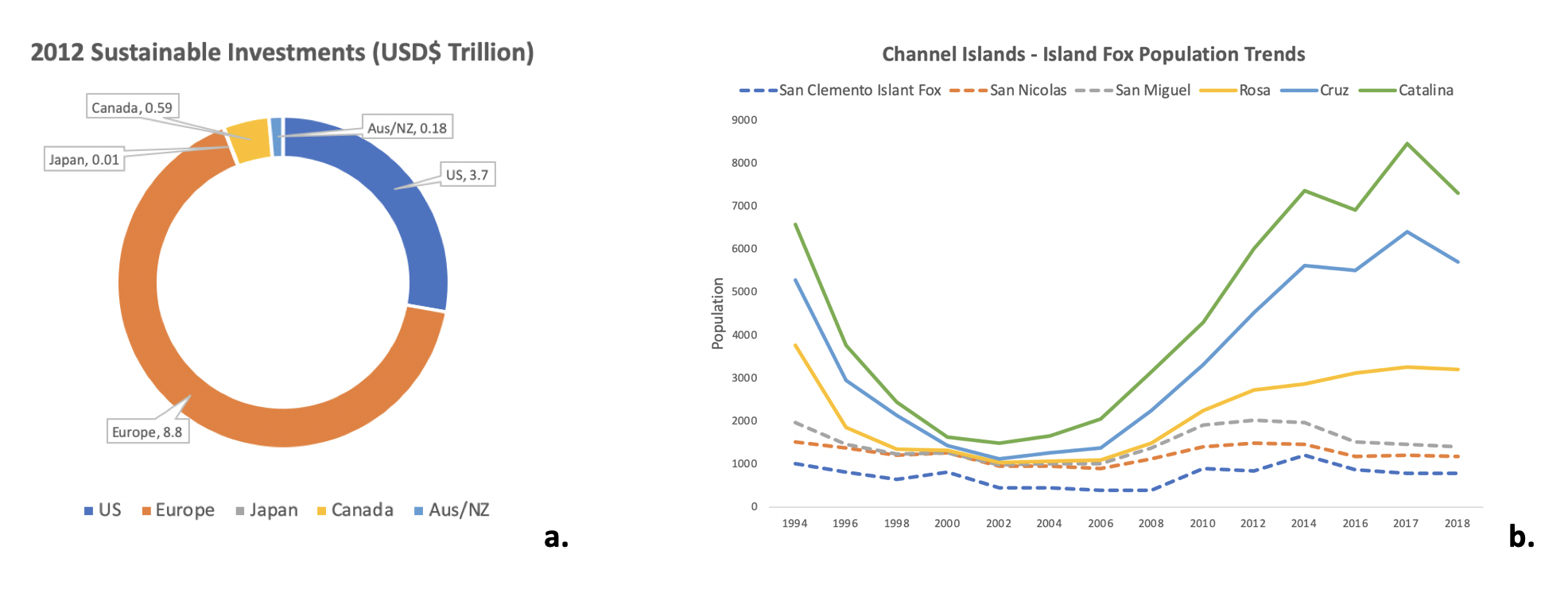
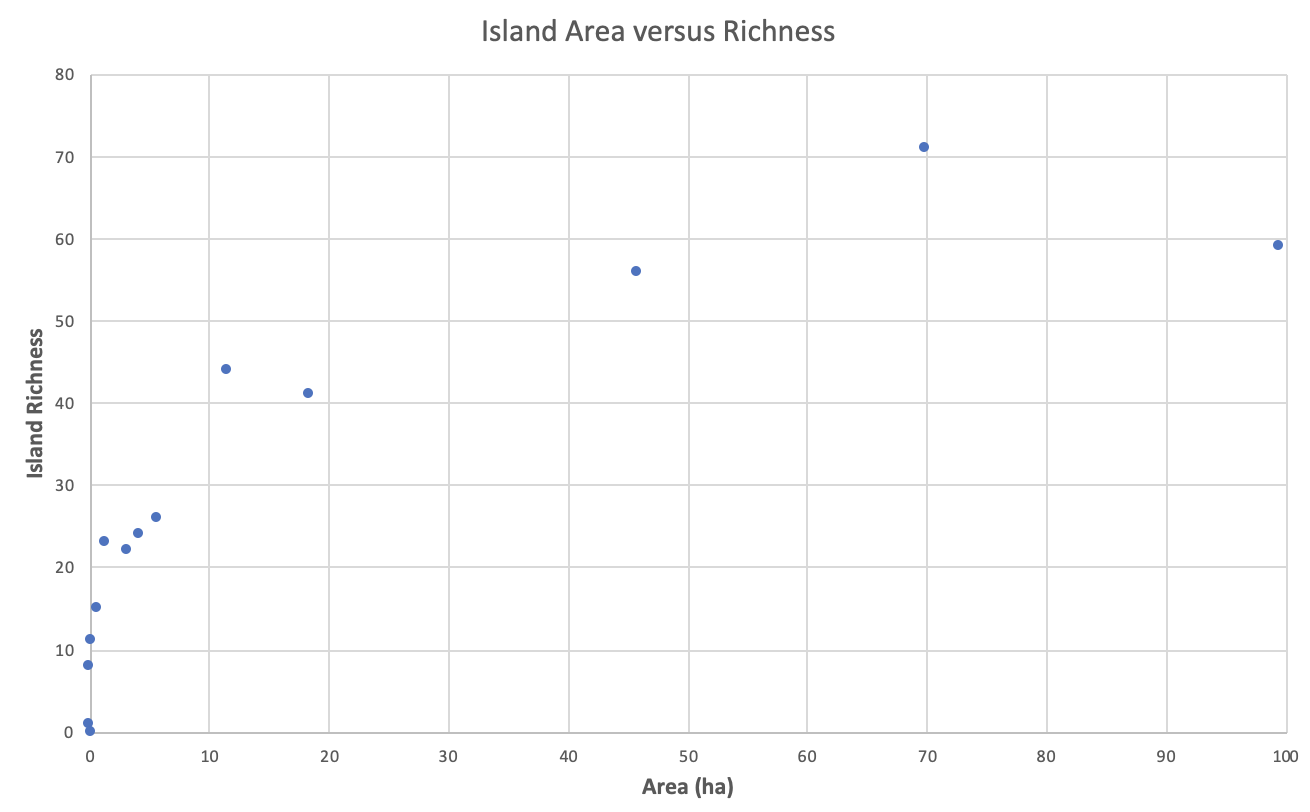
- Gráfico de dispersão — É um gráfico no qual os valores de duas variáveis são plotados ao longo dos eixos horizontal e vertical, o padrão dos pontos resultantes revelando qualquer predefinição de correlação . Os dados são exibidos como uma coleção de pontos, cada um com o valor de uma variável determinando a posição no eixo horizontal e o valor da outra variável determinando a posição no eixo vertical.
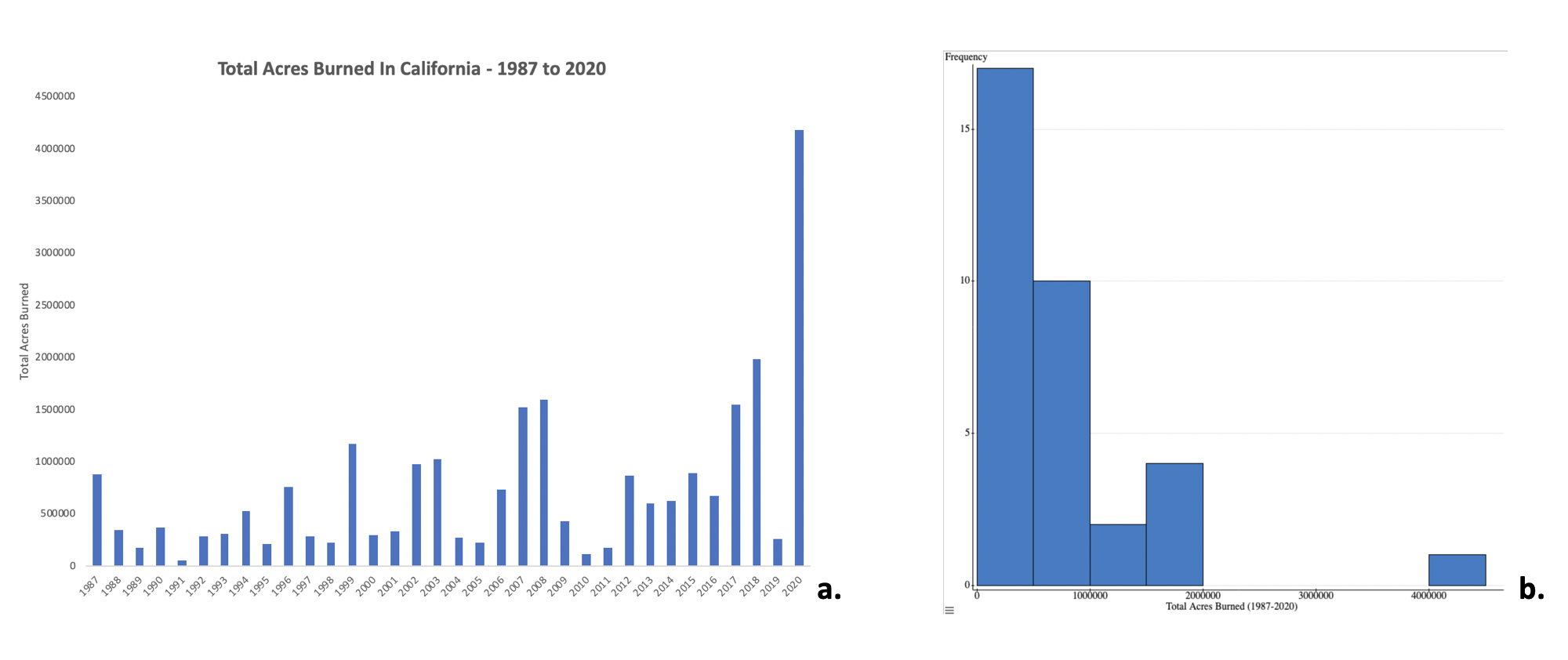
- Barra — Um gráfico ou gráfico que apresenta dados categóricos com barras retangulares com alturas ou comprimentos proporcionais aos valores que elas representam. As barras podem ser plotadas vertical ou horizontalmente.
- Histograma — É uma representação aproximada da distribuição de dados numéricos. Para construir um histograma, a primeira etapa é “dividir” (ou “dividir”) o intervalo de valores, ou seja, dividir todo o intervalo de valores em uma série de intervalos, e depois contar quantos valores estão em cada intervalo. Os compartimentos geralmente são especificados como intervalos consecutivos e não sobrepostos de uma variável. Os compartimentos (intervalos) devem ser adjacentes (o que significa que não há espaços entre eles, como nos gráficos de barras) e geralmente (mas não precisam ser) do mesmo tamanho. Se os compartimentos forem do mesmo tamanho, um retângulo é erguido sobre o compartimento com altura proporcional à frequência — o número de caixas em cada compartimento.
Atribuição
Rachel Schleiger (CC-BY-NC)