
4.7 : Entrepôt de données
- Page ID
- 167115
Alors que les organisations ont commencé à utiliser les bases de données comme pièce maîtresse de leurs opérations, la nécessité de bien comprendre et d'exploiter les données qu'elles collectent est devenue de plus en plus évidente. Cependant, analyser directement les données nécessaires aux opérations quotidiennes n'est pas une bonne idée ; nous ne voulons pas taxer les activités de l'entreprise plus que nécessaire. De plus, les entreprises souhaitent également analyser les données dans un sens historique : comment les données dont nous disposons aujourd'hui se comparent-elles au même ensemble de données à la même période le mois dernier ou l'année dernière ? C'est de ces besoins qu'est né le concept d'entrepôt de données.
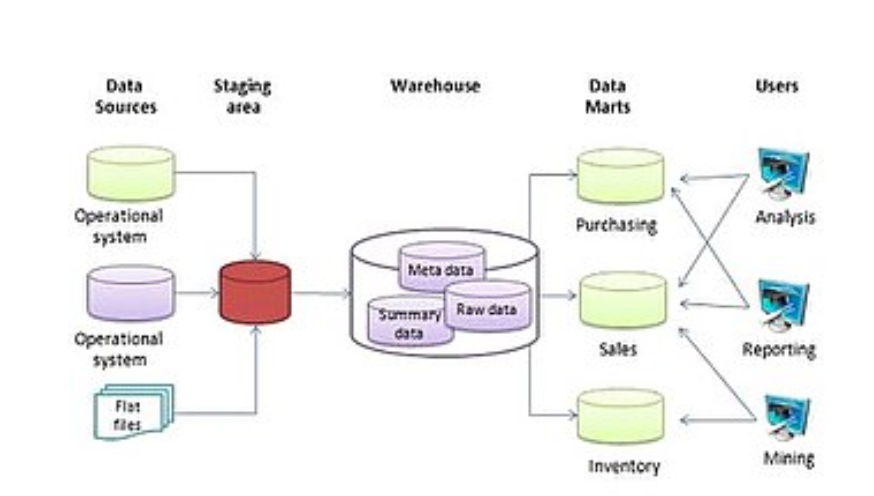
Le concept d'entrepôt de données est simple : extrayez les données d'une ou de plusieurs bases de données de l'organisation et chargez-les dans l'entrepôt de données (qui est lui-même une autre base de données) à des fins de stockage et d'analyse. Cependant, l'exécution de ce concept n'est pas si simple. Un entrepôt de données doit être conçu de telle sorte qu'il réponde aux critères suivants :
- Il utilise des données non opérationnelles. Cela signifie que l'entrepôt de données utilise une copie des données des bases de données actives que l'entreprise utilise dans ses opérations quotidiennes. L'entrepôt de données doit donc extraire les données des bases de données existantes de manière régulière et planifiée.
- Les données varient dans le temps. Cela signifie que chaque fois que des données sont chargées dans l'entrepôt de données, elles reçoivent un horodatage, ce qui permet des comparaisons entre différentes périodes.
- Les données sont standardisées. Comme les données d'un entrepôt de données proviennent généralement de plusieurs sources différentes, il est possible que les données n'utilisent pas les mêmes définitions ou unités. Par exemple, le tableau des événements de notre base de données des clubs étudiants répertorie les dates des événements au format mm/jj/aaaa (par exemple, 01/10/2013). Une table d'une autre base de données peut utiliser le format yy/mm/dd (par exemple, 13/01/10) pour les dates. Pour que l'entrepôt de données corresponde aux dates, un format de date standard devrait être convenu et toutes les données chargées dans l'entrepôt de données devraient être converties pour utiliser ce format standard. Ce processus est appelé extraction-transformation-load (ETL).
Il existe deux écoles de pensée principales lors de la conception d'un entrepôt de données : de bas en haut et de haut en bas. L'approche ascendante commence par la création de petits entrepôts de données, appelés data marts, pour résoudre des problèmes commerciaux spécifiques. Au fur et à mesure que ces data marts sont créés, ils peuvent être combinés dans un entrepôt de données plus vaste. L'approche descendante suggère que nous devrions commencer par créer un entrepôt de données à l'échelle de l'entreprise, puis, à mesure que des besoins commerciaux spécifiques sont identifiés, créer des data marts plus petits à partir de l'entrepôt de données.
Avantages des entrepôts de données
Les entreprises trouvent les entrepôts de données très avantageux pour de nombreuses raisons :
- Possibilité d'intégrer des données provenant de plusieurs systèmes formatés avec différents logiciels et de les compiler pour obtenir des informations plus approfondies.
- Le processus de développement d'un entrepôt de données oblige une organisation à mieux comprendre les données qu'elle ne collecte actuellement et, ce qui est tout aussi important, à savoir quelles données ne sont pas collectées.
- Un entrepôt de données fournit une vue centralisée de toutes les données collectées au sein de l'entreprise et permet de déterminer les données incohérentes.
- Une fois que toutes les données sont identifiées comme cohérentes, une organisation peut générer une version unique de la vérité. Cela est important lorsque l'entreprise souhaite communiquer des statistiques cohérentes la concernant, telles que le chiffre d'affaires ou le nombre d'employés.
- En disposant d'un entrepôt de données, des instantanés des données peuvent être pris au fil du temps. Cela crée un enregistrement historique des données, qui permet une analyse des tendances.
- Un entrepôt de données fournit des outils permettant de combiner les données, ce qui peut fournir de nouvelles informations et analyses.